

This system finds new leads using real-time web intelligence, automatically detects buying signals, and generates personalized outreach based on real business events. Jump straight to the action on GitHub.
You will learn:
- How to build multi-agent systems using CrewAI for specialized prospecting tasks
- How to leverage Bright Data MCP for real-time company and contact intelligence
- How to detect trigger events like hiring, funding, and leadership changes automatically
- How to generate personalized outreach based on live business intelligence
- How to create an automated pipeline from prospect discovery to CRM integration
Let’s Begin!
The Challenge of Modern Sales Development
Traditional sales development relies on manual research, which includes: jumping between LinkedIn profiles, company sites, and news articles to identify prospects. This approach is time-consuming, error-prone, and often leads to outdated contact lists and poorly targeted communication.
Integrating CrewAI with Bright Data automates the entire prospecting workflow, reducing hours of manual work to just minutes.
What We Are Building: Intelligent Sales Development System
You will build a multi-agent AI system that finds companies matching your ideal customer profile. It will track trigger events that show buying intent, gather verified information about decision-makers, and create personalized outreach messages using actual business intelligence. The system connects directly to your CRM to keep a qualified pipeline.
Prerequisites
Set up your development environment with these requirements:
- Python 3.11+ installation
- Bright Data account with MCP access
- OpenAI API key for AI generation
- HubSpot CRM credentials for pipeline integration
Environment Setup
Create your project directory and install dependencies. Start by setting up a clean virtual environment to avoid conflicts with other Python projects.
python -m venv ai_bdr_env
source ai_bdr_env/bin/activate # Windows: ai_bdr_env\Scripts\activate
pip install crewai "crewai-tools[mcp]" openai pandas python-dotenv streamlit requestsCreate environment configuration:
BRIGHT_DATA_API_TOKEN="your_bright_data_api_token"
OPENAI_API_KEY="your_openai_api_key"
HUBSPOT_API_KEY="your_hubspot_api_key"Building the AI BDR System
Now let’s start building the AI agents for our AI BDR System.
Step 1: Bright Data MCP Setup
Create the foundation for web scraping infrastructure that collects data in real time from multiple sources. The MCP client handles all communication with Bright Data’s scraping network.
Create a mcp_client.py file in your project root directory and add the following code:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Target industry for company discovery")
size_range: str = Field(description="Company size range (startup, small, medium, enterprise)")
location: str = Field(default="", description="Geographic location or region")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "Find companies matching ICP criteria using web scraping"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Search for companies using real web search through Bright Data."""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"Error in search query '{query}': {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f"Error searching companies for '{term}': {str(e)}")
return []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
ranges = {'startup': (1, 50), 'small': (51, 200), 'medium': (201, 1000)}
min_size, max_size = ranges.get(size_range, (0, 999999))
return min_size <= count <= max_size
def _perform_company_search(self, query):
"""Perform company search using Bright Data MCP."""
search_result = safe_mcp_call(self.mcp, 'search_company_news', query)
if search_result and search_result.get('results'):
return self._extract_companies_from_mcp_results(search_result['results'], query)
else:
print(f"No MCP results for: {query}")
return []
def _filter_unique_companies(self, companies):
"""Filter out duplicate companies."""
seen_names = set()
unique_companies = []
for company in companies:
name_key = company.get('name', '').lower()
if name_key and name_key not in seen_names:
seen_names.add(name_key)
unique_companies.append(company)
return unique_companies
def _extract_companies_from_mcp_results(self, mcp_results, original_query):
"""Extract company information from MCP search results."""
companies = []
for result in mcp_results[:10]:
try:
title = result.get('title', '')
url = result.get('url', '')
snippet = result.get('snippet', '')
company_name = self._extract_company_name_from_result(title, url)
if company_name and len(company_name) > 2:
domain = self._extract_domain_from_url(url)
industry = self._extract_industry_from_query(original_query)
companies.append({
'name': company_name,
'domain': domain,
'industry': industry
})
except Exception as e:
print(f"Error extracting company from MCP result: {str(e)}")
continue
return companies
def _extract_company_name_from_result(self, title, url):
"""Extract company name from search result title or URL."""
import re
if title:
title_clean = re.sub(r'[\|\-\—\–].*$', '', title).strip()
title_clean = re.sub(r'\s+(Inc|Corp|LLC|Ltd|Solutions|Systems|Technologies|Software|Platform|Company)$', '', title_clean, flags=re.IGNORECASE)
if len(title_clean) > 2 and len(title_clean) < 50:
return title_clean
if url:
domain_parts = url.split('/')[2].split('.')
if len(domain_parts) > 1:
return domain_parts[0].title()
return None
def _extract_domain_from_url(self, url):
"""Extract domain from URL."""
return extract_domain_from_url(url)
def _extract_industry_from_query(self, query):
"""Extract industry from search query."""
query_lower = query.lower()
industry_mappings = {
'saas': 'SaaS',
'fintech': 'FinTech',
'ecommerce': 'E-commerce',
'healthcare': 'Healthcare',
'ai': 'AI/ML',
'machine learning': 'AI/ML',
'artificial intelligence': 'AI/ML'
}
for keyword, industry in industry_mappings.items():
if keyword in query_lower:
return industry
return 'Technology'
def create_company_discovery_agent(mcp_client):
return Agent(
role='Company Discovery Specialist',
goal='Find high-quality prospects matching ICP criteria',
backstory='Expert at identifying potential customers using real-time web intelligence.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)This MCP client manages all web scraping tasks using Bright Data’s AI infrastructure. It offers reliable access to LinkedIn company pages, corporate websites, funding databases, and news sources. The client takes care of connection pooling and automatically addresses anti-bot protections.
Step 2: Company Discovery Agent
Transform your ideal customer profile criteria into a smart discovery system that finds companies matching your specific requirements. The agent searches multiple sources and improves company data with business intelligence.
First, create an agents folder in your project root. Then create an agents/company_discovery.py file and add the following code:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Target industry for company discovery")
size_range: str = Field(description="Company size range (startup, small, medium, enterprise)")
location: str = Field(default="", description="Geographic location or region")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "Find companies matching ICP criteria using web scraping"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Search for companies using real web search through Bright Data."""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"Error in search query '{query}': {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f"Error searching companies for '{term}': {str(e)}")
return []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
ranges = {'startup': (1, 50), 'small': (51, 200), 'medium': (201, 1000)}
min_size, max_size = ranges.get(size_range, (0, 999999))
return min_size <= count <= max_size
def create_company_discovery_agent(mcp_client):
return Agent(
role='Company Discovery Specialist',
goal='Find high-quality prospects matching ICP criteria',
backstory='Expert at identifying potential customers using real-time web intelligence.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)The discovery agent searches several data sources to find companies that fit your ideal customer profile. It adds business information from LinkedIn and corporate websites for each company. Then, it filters the results based on scoring criteria you can set. The deduplication process keeps prospect lists clean, avoiding duplicate entries.
Step 3: Trigger Detection Agent
Monitor business events that show buying intent and the best timing for outreach. The agent looks at hiring patterns, funding announcements, leadership changes, and expansion signals to prioritize prospects.
Create an agents/trigger_detection.py file and add the following code:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime, timedelta
from typing import Any, List
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call
class TriggerDetectionInput(BaseModel):
companies: List[dict] = Field(description="List of companies to analyze for trigger events")
class TriggerDetectionTool(BaseTool):
name: str = "detect_triggers"
description: str = "Find hiring signals, funding news, leadership changes"
args_schema: type[BaseModel] = TriggerDetectionInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
triggers = []
hiring_signals = self._detect_hiring_triggers(company)
triggers.extend(hiring_signals)
funding_signals = self._detect_funding_triggers(company)
triggers.extend(funding_signals)
leadership_signals = self._detect_leadership_triggers(company)
triggers.extend(leadership_signals)
expansion_signals = self._detect_expansion_triggers(company)
triggers.extend(expansion_signals)
company['trigger_events'] = triggers
company['trigger_score'] = self._calculate_trigger_score(triggers)
return sorted(companies, key=lambda x: x.get('trigger_score', 0), reverse=True)
def _detect_hiring_triggers(self, company):
"""Detect hiring triggers using LinkedIn data."""
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
triggers = []
if linkedin_data:
hiring_posts = linkedin_data.get('hiring_posts', [])
recent_activity = linkedin_data.get('recent_activity', [])
if hiring_posts:
triggers.append({
'type': 'hiring_spike',
'severity': 'high',
'description': f"Active hiring detected at {company['name']} - {len(hiring_posts)} open positions",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
if recent_activity:
triggers.append({
'type': 'company_activity',
'severity': 'medium',
'description': f"Increased LinkedIn activity at {company['name']}",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
return triggers
def _detect_funding_triggers(self, company):
"""Detect funding triggers using news search."""
funding_data = safe_mcp_call(self.mcp, 'search_funding_news', company['name'])
triggers = []
if funding_data and funding_data.get('results'):
triggers.append({
'type': 'funding_round',
'severity': 'high',
'description': f"Recent funding activity detected at {company['name']}",
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
return triggers
def _detect_leadership_triggers(self, company):
"""Detect leadership changes using news search."""
return self._detect_keyword_triggers(
company, 'leadership_change', 'medium',
['ceo', 'cto', 'vp', 'hired', 'joins', 'appointed'],
f"Leadership changes detected at {company['name']}"
)
def _detect_expansion_triggers(self, company):
"""Detect business expansion using news search."""
return self._detect_keyword_triggers(
company, 'expansion', 'medium',
['expansion', 'new office', 'opening', 'market'],
f"Business expansion detected at {company['name']}"
)
def _detect_keyword_triggers(self, company, trigger_type, severity, keywords, description):
"""Generic method to detect triggers based on keywords in news."""
news_data = safe_mcp_call(self.mcp, 'search_company_news', company['name'])
triggers = []
if news_data and news_data.get('results'):
for result in news_data['results']:
if any(keyword in str(result).lower() for keyword in keywords):
triggers.append({
'type': trigger_type,
'severity': severity,
'description': description,
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
break
return triggers
def _calculate_trigger_score(self, triggers):
severity_weights = {'high': 15, 'medium': 10, 'low': 5}
return sum(severity_weights.get(t.get('severity', 'low'), 5) for t in triggers)
def create_trigger_detection_agent(mcp_client):
return Agent(
role='Trigger Event Analyst',
goal='Identify buying signals and optimal timing for outreach',
backstory='Expert at detecting business events that indicate readiness to buy.',
tools=[TriggerDetectionTool(mcp_client)],
verbose=True
)The trigger detection system monitors various business signals that show buying intent and the best times for outreach. It looks at hiring patterns from LinkedIn job postings, tracks funding announcements in news sources, watches for leadership changes, and identifies expansion activities. Each trigger gets a severity score that helps prioritize prospects based on urgency and the size of the opportunity.
Step 4: Contact Research Agent
Find and verify contact information for decision-makers while considering confidence scores from various data sources. The agent prioritizes contacts based on their role and the quality of the data.
Create an agents/contact_research.py file and add the following code:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import re
from .utils import validate_companies_input, safe_mcp_call, validate_email, deduplicate_by_key
class ContactResearchInput(BaseModel):
companies: List[dict] = Field(description="List of companies to research contacts for")
target_roles: List[str] = Field(description="List of target roles to find contacts for")
class ContactResearchTool(BaseTool):
name: str = "research_contacts"
description: str = "Find and verify decision-maker contact information using MCP"
args_schema: type[BaseModel] = ContactResearchInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies, target_roles) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
if not isinstance(target_roles, list):
target_roles = [target_roles] if target_roles else []
for company in companies:
contacts = []
for role in target_roles:
role_contacts = self._search_contacts_by_role(company, role)
for contact in role_contacts:
enriched = self._enrich_contact_data(contact, company)
if self._validate_contact(enriched):
contacts.append(enriched)
company['contacts'] = self._deduplicate_contacts(contacts)
company['contact_score'] = self._calculate_contact_quality(contacts)
return companies
def _search_contacts_by_role(self, company, role):
"""Search for contacts by role using MCP."""
contacts = []
search_query = f"{company['name']} {role} LinkedIn contact"
search_result = safe_mcp_call(self.mcp, 'search_company_news', search_query)
if search_result and search_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(search_result['results'], role))
if not contacts:
contact_query = f"{company['name']} {role} email contact"
contact_result = safe_mcp_call(self.mcp, 'search_company_news', contact_query)
if contact_result and contact_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(contact_result['results'], role))
return contacts[:3]
def _extract_contacts_from_mcp_results(self, results, role):
"""Extract contact information from MCP search results."""
contacts = []
for result in results:
try:
title = result.get('title', '')
snippet = result.get('snippet', '')
url = result.get('url', '')
names = self._extract_names_from_text(title + ' ' + snippet)
for name_parts in names:
if len(name_parts) >= 2:
first_name, last_name = name_parts[0], ' '.join(name_parts[1:])
contacts.append({
'first_name': first_name,
'last_name': last_name,
'title': role,
'linkedin_url': url if 'linkedin' in url else '',
'data_sources': 1,
'source': 'mcp_search'
})
if len(contacts) >= 2:
break
except Exception as e:
print(f"Error extracting contact from result: {str(e)}")
continue
return contacts
def _extract_names_from_text(self, text):
"""Extract likely names from text."""
import re
name_patterns = [
r'\b([A-Z][a-z]+)\s+([A-Z][a-z]+)\b',
r'\b([A-Z][a-z]+)\s+([A-Z]\.?\s*[A-Z][a-z]+)\b',
r'\b([A-Z][a-z]+)\s+([A-Z][a-z]+)\s+([A-Z][a-z]+)\b'
]
names = []
for pattern in name_patterns:
matches = re.findall(pattern, text)
for match in matches:
if isinstance(match, tuple):
names.append(list(match))
return names[:3]
def _enrich_contact_data(self, contact, company):
if not contact.get('email'):
contact['email'] = self._generate_email(
contact['first_name'],
contact['last_name'],
company.get('domain', '')
)
contact['email_valid'] = validate_email(contact.get('email', ''))
contact['confidence_score'] = self._calculate_confidence(contact)
return contact
def _generate_email(self, first, last, domain):
if not all([first, last, domain]):
return ""
return f"{first.lower()}.{last.lower()}@{domain}"
def _calculate_confidence(self, contact):
score = 0
if contact.get('linkedin_url'): score += 30
if contact.get('email_valid'): score += 25
if contact.get('data_sources', 0) > 1: score += 20
if all(contact.get(f) for f in ['first_name', 'last_name', 'title']): score += 25
return score
def _validate_contact(self, contact):
required = ['first_name', 'last_name', 'title']
return (all(contact.get(f) for f in required) and
contact.get('confidence_score', 0) >= 50)
def _deduplicate_contacts(self, contacts):
unique = deduplicate_by_key(
contacts,
lambda c: c.get('email', '') or f"{c.get('first_name', '')}_{c.get('last_name', '')}"
)
return sorted(unique, key=lambda x: x.get('confidence_score', 0), reverse=True)
def _calculate_contact_quality(self, contacts):
if not contacts:
return 0
avg_confidence = sum(c.get('confidence_score', 0) for c in contacts) / len(contacts)
high_quality = sum(1 for c in contacts if c.get('confidence_score', 0) >= 75)
return min(avg_confidence + (high_quality * 5), 100)
def create_contact_research_agent(mcp_client):
return Agent(
role='Contact Intelligence Specialist',
goal='Find accurate contact information for decision-makers using MCP',
backstory='Expert at finding and verifying contact information using advanced MCP search tools.',
tools=[ContactResearchTool(mcp_client)],
verbose=True
)The contact research system identifies decision-makers by searching roles on LinkedIn and company websites. It generates email addresses using typical corporate patterns and checks contact information through various verification methods. The system assigns confidence scores based on the quality of the data sources. The deduplication process keeps contact lists clean, prioritizing them by verification confidence.
Step 5: Intelligent Message Generation
Transform business intelligence into personalized outreach messages that mention specific trigger events and show research. The generator creates several message formats for different channels.
Create an agents/message_generation.py file and add the following code:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import openai
import os
class MessageGenerationInput(BaseModel):
companies: List[dict] = Field(description="List of companies with contacts to generate messages for")
message_type: str = Field(default="cold_email", description="Type of message to generate (cold_email, linkedin_message, follow_up)")
class MessageGenerationTool(BaseTool):
name: str = "generate_messages"
description: str = "Create personalized outreach based on company intelligence"
args_schema: type[BaseModel] = MessageGenerationInput
client: Any = None
def __init__(self):
super().__init__()
self.client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def _run(self, companies, message_type="cold_email") -> list:
# Ensure companies is a list
if not isinstance(companies, list):
print(f"Warning: Expected list of companies, got {type(companies)}")
return []
if not companies:
print("No companies provided for message generation")
return []
for company in companies:
if not isinstance(company, dict):
print(f"Warning: Expected company dict, got {type(company)}")
continue
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
message = self._generate_personalized_message(contact, company, message_type)
contact['generated_message'] = message
contact['message_quality_score'] = self._calculate_message_quality(message, company)
return companies
def _generate_personalized_message(self, contact, company, message_type):
context = self._build_message_context(contact, company)
if message_type == "cold_email":
return self._generate_cold_email(context)
elif message_type == "linkedin_message":
return self._generate_linkedin_message(context)
else:
return self._generate_cold_email(context)
def _build_message_context(self, contact, company):
triggers = company.get('trigger_events', [])
primary_trigger = triggers[0] if triggers else None
return {
'contact_name': contact.get('first_name', ''),
'contact_title': contact.get('title', ''),
'company_name': company.get('name', ''),
'industry': company.get('industry', ''),
'primary_trigger': primary_trigger,
'trigger_count': len(triggers)
}
def _generate_cold_email(self, context):
trigger_text = ""
if context['primary_trigger']:
trigger_text = f"I noticed {context['company_name']} {context['primary_trigger']['description'].lower()}."
prompt = f"""Write a personalized cold email:
Contact: {context['contact_name']}, {context['contact_title']} at {context['company_name']}
Industry: {context['industry']}
Context: {trigger_text}
Requirements:
- Subject line that references the trigger event
- Personal greeting with first name
- Opening that demonstrates research
- Brief value proposition
- Clear call-to-action
- Maximum 120 words
Format as:
SUBJECT: [subject line]
BODY: [email body]"""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=300
)
return self._parse_email_response(response.choices[0].message.content)
def _generate_linkedin_message(self, context):
prompt = f"""Write a LinkedIn connection request (max 300 chars):
Contact: {context['contact_name']} at {context['company_name']}
Context: {context.get('primary_trigger', {}).get('description', '')}
Be professional, reference their company activity, no direct sales pitch."""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=100
)
return {
'subject': 'LinkedIn Connection Request',
'body': response.choices[0].message.content.strip()
}
def _parse_email_response(self, response):
lines = response.strip().split('\n')
subject = ""
body_lines = []
for line in lines:
if line.startswith('SUBJECT:'):
subject = line.replace('SUBJECT:', '').strip()
elif line.startswith('BODY:'):
body_lines.append(line.replace('BODY:', '').strip())
elif body_lines:
body_lines.append(line)
return {
'subject': subject,
'body': '\n'.join(body_lines).strip()
}
def _calculate_message_quality(self, message, company):
score = 0
body = message.get('body', '').lower()
if company.get('name', '').lower() in message.get('subject', '').lower():
score += 25
if company.get('trigger_events') and any(t.get('type', '') in body for t in company['trigger_events']):
score += 30
if len(body.split()) <= 120:
score += 20
if any(word in body for word in ['call', 'meeting', 'discuss', 'connect']):
score += 25
return score
def create_message_generation_agent():
return Agent(
role='Personalization Specialist',
goal='Create compelling personalized outreach that gets responses',
backstory='Expert at crafting messages that demonstrate research and provide value.',
tools=[MessageGenerationTool()],
verbose=True
)The message generation system turns business intelligence into personalized outreach. It references specific trigger events and shows detailed research. It creates subject lines that fit the context, personalized greetings, and value propositions that match each prospect’s situation. The system generates various message formats that work well for different channels. It keeps the quality of personalization consistent.
Step 6: Lead Scoring and Pipeline Manager
Score prospects using various intelligence factors, then automatically export qualified leads to your CRM system. The manager prioritizes leads based on fit, timing, and data quality.
Create an agents/pipeline_manager.py file and add the following code:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime
from typing import List
from pydantic import BaseModel, Field
import requests
import os
from .utils import validate_companies_input
class LeadScoringInput(BaseModel):
companies: List[dict] = Field(description="List of companies to score")
class LeadScoringTool(BaseTool):
name: str = "score_leads"
description: str = "Score leads based on multiple intelligence factors"
args_schema: type[BaseModel] = LeadScoringInput
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
score_breakdown = self._calculate_lead_score(company)
company['lead_score'] = score_breakdown['total_score']
company['score_breakdown'] = score_breakdown
company['lead_grade'] = self._assign_grade(score_breakdown['total_score'])
return sorted(companies, key=lambda x: x.get('lead_score', 0), reverse=True)
def _calculate_lead_score(self, company):
breakdown = {
'icp_score': min(company.get('icp_score', 0) * 0.3, 25),
'trigger_score': min(company.get('trigger_score', 0) * 2, 30),
'contact_score': min(company.get('contact_score', 0) * 0.2, 20),
'timing_score': self._assess_timing(company),
'company_health': self._assess_health(company)
}
breakdown['total_score'] = sum(breakdown.values())
return breakdown
def _assess_timing(self, company):
triggers = company.get('trigger_events', [])
if not triggers:
return 0
recent_triggers = sum(1 for t in triggers if 'high' in t.get('severity', ''))
return min(recent_triggers * 8, 15)
def _assess_health(self, company):
score = 0
if company.get('trigger_events'):
score += 5
if company.get('employee_count', 0) > 50:
score += 5
return score
def _assign_grade(self, score):
if score >= 80: return 'A'
elif score >= 65: return 'B'
elif score >= 50: return 'C'
else: return 'D'
class CRMIntegrationInput(BaseModel):
companies: List[dict] = Field(description="List of companies to export to CRM")
min_grade: str = Field(default="B", description="Minimum lead grade to export (A, B, C, D)")
class CRMIntegrationTool(BaseTool):
name: str = "crm_integration"
description: str = "Export qualified leads to HubSpot CRM"
args_schema: type[BaseModel] = CRMIntegrationInput
def _run(self, companies, min_grade='B') -> dict:
companies = validate_companies_input(companies)
if not companies:
return {"message": "No companies provided for CRM export", "success": 0, "errors": 0}
qualified = [c for c in companies if isinstance(c, dict) and c.get('lead_grade', 'D') in ['A', 'B']]
if not os.getenv("HUBSPOT_API_KEY"):
return {"error": "HubSpot API key not configured", "success": 0, "errors": 0}
results = {"success": 0, "errors": 0, "details": []}
for company in qualified:
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
result = self._create_hubspot_contact(contact, company)
if result.get('success'):
results['success'] += 1
else:
results['errors'] += 1
results['details'].append(result)
return results
def _create_hubspot_contact(self, contact, company):
api_key = os.getenv("HUBSPOT_API_KEY")
if not api_key:
return {"success": False, "error": "HubSpot API key not configured"}
url = "https://api.hubapi.com/crm/v3/objects/contacts"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
trigger_summary = "; ".join([
f"{t.get('type', '')}: {t.get('description', '')}"
for t in company.get('trigger_events', [])
])
email = contact.get('email', '').strip()
if not email:
return {"success": False, "error": "Contact email is required", "contact": contact.get('first_name', 'Unknown')}
properties = {
"email": email,
"firstname": contact.get('first_name', ''),
"lastname": contact.get('last_name', ''),
"jobtitle": contact.get('title', ''),
"company": company.get('name', ''),
"website": f"https://{company.get('domain', '')}" if company.get('domain') else "",
"hs_lead_status": "NEW",
"lifecyclestage": "lead"
}
if company.get('lead_score'):
properties["lead_score"] = str(company.get('lead_score', 0))
if company.get('lead_grade'):
properties["lead_grade"] = company.get('lead_grade', 'D')
if trigger_summary:
properties["trigger_events"] = trigger_summary[:1000]
if contact.get('confidence_score'):
properties["contact_confidence"] = str(contact.get('confidence_score', 0))
properties["ai_discovery_date"] = datetime.now().isoformat()
try:
response = requests.post(url, json={"properties": properties}, headers=headers, timeout=30)
if response.status_code == 201:
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": response.json().get('id')
}
elif response.status_code == 409:
existing_contact = response.json()
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": existing_contact.get('id'),
"note": "Contact already exists"
}
else:
error_detail = response.text if response.text else f"HTTP {response.status_code}"
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"API Error: {error_detail}"
}
except requests.exceptions.RequestException as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Network error: {str(e)}"
}
except Exception as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Unexpected error: {str(e)}"
}
def create_pipeline_manager_agent():
return Agent(
role='Pipeline Manager',
goal='Score leads and manage CRM integration for qualified prospects',
backstory='Expert at evaluating prospect quality and managing sales pipeline.',
tools=[LeadScoringTool(), CRMIntegrationTool()],
verbose=True
)The lead scoring system evaluates prospects in several areas, including how well they fit the ideal customer profile, the urgency of trigger events, the quality of contact data, and timing factors. It provides detailed score breakdowns that allow for data-driven prioritization and automatically assigns letter grades for quick qualification. The CRM integration tool exports qualified leads directly to HubSpot, ensuring that all intelligence data is properly formatted for the sales team to follow up.
Step 6.1: Shared Utilities
Before creating the main application, create an agents/utils.py file with shared utility functions used across all agents:
"""
Shared utility functions for all agent modules.
"""
from typing import List, Dict, Any
import re
def validate_companies_input(companies: Any) -> List[Dict]:
"""Validate and normalize companies input across all agents."""
if isinstance(companies, dict) and 'companies' in companies:
companies = companies['companies']
if not isinstance(companies, list):
print(f"Warning: Expected list of companies, got {type(companies)}")
return []
if not companies:
print("No companies provided")
return []
valid_companies = []
for company in companies:
if isinstance(company, dict):
valid_companies.append(company)
else:
print(f"Warning: Expected company dict, got {type(company)}")
return valid_companies
def safe_mcp_call(mcp_client, method_name: str, *args, **kwargs) -> Dict:
"""Safely call MCP methods with consistent error handling."""
try:
method = getattr(mcp_client, method_name)
result = method(*args, **kwargs)
return result if result and not result.get('error') else {}
except Exception as e:
print(f"Error calling MCP {method_name}: {str(e)}")
return {}
def validate_email(email: str) -> bool:
"""Validate email format."""
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))
def deduplicate_by_key(items: List[Dict], key_func) -> List[Dict]:
"""Remove duplicates from list of dicts using a key function."""
seen = set()
unique_items = []
for item in items:
key = key_func(item)
if key and key not in seen:
seen.add(key)
unique_items.append(item)
return unique_items
def extract_domain_from_url(url: str) -> str:
"""Extract domain from URL with fallback parsing."""
if not url:
return ""
try:
from urllib.parse import urlparse
parsed = urlparse(url)
return parsed.netloc
except:
if '//' in url:
return url.split('//')[1].split('/')[0]
return ""You’ll also need to create an empty agents/__init__.py file to make the agents folder a Python package.
Step 7: System Orchestration
Create the main Streamlit application that coordinates all agents in an intelligent workflow. The interface gives real-time feedback and allows users to customize parameters for different prospecting scenarios.
Create an ai_bdr_system.py file in your project root directory and add the following code:
import streamlit as st
import os
from dotenv import load_dotenv
from crewai import Crew, Process, Task
import pandas as pd
from datetime import datetime
import json
from mcp_client import Bright DataMCP
from agents.company_discovery import create_company_discovery_agent
from agents.trigger_detection import create_trigger_detection_agent
from agents.contact_research import create_contact_research_agent
from agents.message_generation import create_message_generation_agent
from agents.pipeline_manager import create_pipeline_manager_agent
load_dotenv()
st.set_page_config(
page_title="AI BDR/SDR System",
page_icon="🤖",
layout="wide"
)
st.title("🤖 AI BDR/SDR Agent System")
st.markdown("**Real-time prospecting with multi-agent intelligence and trigger-based personalization**")
if 'workflow_results' not in st.session_state:
st.session_state.workflow_results = None
with st.sidebar:
try:
st.image("bright-data-logo.png", width=200)
st.markdown("---")
except:
st.markdown("**🌐 Powered by Bright Data**")
st.markdown("---")
st.header("⚙️ Configuration")
st.subheader("Ideal Customer Profile")
industry = st.selectbox("Industry", ["SaaS", "FinTech", "E-commerce", "Healthcare", "AI/ML"])
size_range = st.selectbox("Company Size", ["startup", "small", "medium", "enterprise"])
location = st.text_input("Location (optional)", placeholder="San Francisco, NY, etc.")
max_companies = st.slider("Max Companies", 5, 50, 20)
st.subheader("Target Decision Makers")
all_roles = ["CEO", "CTO", "VP Engineering", "Head of Product", "VP Sales", "CMO", "CFO"]
target_roles = st.multiselect("Roles", all_roles, default=["CEO", "CTO", "VP Engineering"])
st.subheader("Outreach Configuration")
message_types = st.multiselect(
"Message Types",
["cold_email", "linkedin_message", "follow_up"],
default=["cold_email"]
)
with st.expander("Advanced Intelligence"):
enable_competitive = st.checkbox("Competitive Intelligence", value=True)
enable_validation = st.checkbox("Multi-source Validation", value=True)
min_lead_grade = st.selectbox("Min CRM Export Grade", ["A", "B", "C"], index=1)
st.divider()
st.subheader("🔗 API Status")
apis = [
("Bright Data", "BRIGHT_DATA_API_TOKEN", "🌐"),
("OpenAI", "OPENAI_API_KEY", "🧠"),
("HubSpot CRM", "HUBSPOT_API_KEY", "📊")
]
for name, env_var, icon in apis:
if os.getenv(env_var):
st.success(f"{icon} {name} Connected")
else:
if name == "HubSpot CRM":
st.warning(f"⚠️ {name} Required for CRM export")
elif name == "Bright Data":
st.error(f"❌ {name} Missing")
if st.button("🔧 Configuration Help", key="bright_data_help"):
st.info("""
**Bright Data Setup Required:**
1. Get credentials from Bright Data dashboard
2. Update .env file with:
```
BRIGHT_DATA_API_TOKEN=your_password
WEB_UNLOCKER_ZONE=lum-customer-username-zone-zonename
```
3. See BRIGHT_DATA_SETUP.md for detailed guide
**Current Error**: 407 Invalid Auth = Wrong credentials
""")
else:
st.error(f"❌ {name} Missing")
col1, col2 = st.columns([3, 1])
with col1:
st.subheader("🚀 AI Prospecting Workflow")
if st.button("Start Multi-Agent Prospecting", type="primary", use_container_width=True):
required_keys = ["BRIGHT_DATA_API_TOKEN", "OPENAI_API_KEY"]
missing_keys = [key for key in required_keys if not os.getenv(key)]
if missing_keys:
st.error(f"Missing required API keys: {', '.join(missing_keys)}")
st.stop()
progress_bar = st.progress(0)
status_text = st.empty()
try:
mcp_client = Bright DataMCP()
discovery_agent = create_company_discovery_agent(mcp_client)
trigger_agent = create_trigger_detection_agent(mcp_client)
contact_agent = create_contact_research_agent(mcp_client)
message_agent = create_message_generation_agent()
pipeline_agent = create_pipeline_manager_agent()
status_text.text("🔍 Discovering companies matching ICP...")
progress_bar.progress(15)
discovery_task = Task(
description=f"Find {max_companies} companies in {industry} ({size_range} size) in {location}",
expected_output="List of companies with ICP scores and intelligence",
agent=discovery_agent
)
discovery_crew = Crew(
agents=[discovery_agent],
tasks=[discovery_task],
process=Process.sequential
)
companies = discovery_agent.tools[0]._run(industry, size_range, location)
st.success(f"✅ Discovered {len(companies)} companies")
status_text.text("🎯 Analyzing trigger events and buying signals...")
progress_bar.progress(30)
trigger_task = Task(
description="Detect hiring spikes, funding rounds, leadership changes, and expansion signals",
expected_output="Companies with trigger events and scores",
agent=trigger_agent
)
trigger_crew = Crew(
agents=[trigger_agent],
tasks=[trigger_task],
process=Process.sequential
)
companies_with_triggers = trigger_agent.tools[0]._run(companies)
total_triggers = sum(len(c.get('trigger_events', [])) for c in companies_with_triggers)
st.success(f"✅ Detected {total_triggers} trigger events")
progress_bar.progress(45)
status_text.text("👥 Finding decision-maker contacts...")
contact_task = Task(
description=f"Find verified contacts for roles: {', '.join(target_roles)}",
expected_output="Companies with decision-maker contact information",
agent=contact_agent
)
contact_crew = Crew(
agents=[contact_agent],
tasks=[contact_task],
process=Process.sequential
)
companies_with_contacts = contact_agent.tools[0]._run(companies_with_triggers, target_roles)
total_contacts = sum(len(c.get('contacts', [])) for c in companies_with_contacts)
st.success(f"✅ Found {total_contacts} verified contacts")
progress_bar.progress(60)
status_text.text("✍️ Generating personalized outreach messages...")
message_task = Task(
description=f"Generate {', '.join(message_types)} for each contact using trigger intelligence",
expected_output="Companies with personalized messages",
agent=message_agent
)
message_crew = Crew(
agents=[message_agent],
tasks=[message_task],
process=Process.sequential
)
companies_with_messages = message_agent.tools[0]._run(companies_with_contacts, message_types[0])
total_messages = sum(len(c.get('contacts', [])) for c in companies_with_messages)
st.success(f"✅ Generated {total_messages} personalized messages")
progress_bar.progress(75)
status_text.text("📊 Scoring leads and updating CRM...")
pipeline_task = Task(
description=f"Score leads and export Grade {min_lead_grade}+ to HubSpot CRM",
expected_output="Scored leads with CRM integration results",
agent=pipeline_agent
)
pipeline_crew = Crew(
agents=[pipeline_agent],
tasks=[pipeline_task],
process=Process.sequential
)
final_companies = pipeline_agent.tools[0]._run(companies_with_messages)
qualified_leads = [c for c in final_companies if c.get('lead_grade', 'D') in ['A', 'B']]
crm_results = {"success": 0, "errors": 0}
if os.getenv("HUBSPOT_API_KEY"):
crm_results = pipeline_agent.tools[1]._run(final_companies, min_lead_grade)
progress_bar.progress(100)
status_text.text("✅ Workflow completed successfully!")
st.session_state.workflow_results = {
'companies': final_companies,
'total_companies': len(final_companies),
'total_triggers': total_triggers,
'total_contacts': total_contacts,
'qualified_leads': len(qualified_leads),
'crm_results': crm_results,
'timestamp': datetime.now()
}
except Exception as e:
st.error(f"❌ Workflow failed: {str(e)}")
st.write("Please check your API configurations and try again.")
if st.session_state.workflow_results:
results = st.session_state.workflow_results
st.markdown("---")
st.subheader("📊 Workflow Results")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Companies Analyzed", results['total_companies'])
with col2:
st.metric("Trigger Events", results['total_triggers'])
with col3:
st.metric("Contacts Found", results['total_contacts'])
with col4:
st.metric("Qualified Leads", results['qualified_leads'])
if results['crm_results']['success'] > 0 or results['crm_results']['errors'] > 0:
st.subheader("🔄 HubSpot CRM Integration")
col1, col2 = st.columns(2)
with col1:
st.metric("Exported to CRM", results['crm_results']['success'], delta="contacts")
with col2:
if results['crm_results']['errors'] > 0:
st.metric("Export Errors", results['crm_results']['errors'], delta_color="inverse")
st.subheader("🏢 Company Intelligence")
for company in results['companies'][:10]:
with st.expander(f"📋 {company.get('name', 'Unknown')} - Grade {company.get('lead_grade', 'D')} (Score: {company.get('lead_score', 0):.0f})"):
col1, col2 = st.columns(2)
with col1:
st.write(f"**Industry:** {company.get('industry', 'Unknown')}")
st.write(f"**Domain:** {company.get('domain', 'Unknown')}")
st.write(f"**ICP Score:** {company.get('icp_score', 0)}")
triggers = company.get('trigger_events', [])
if triggers:
st.write("**🎯 Trigger Events:**")
for trigger in triggers:
severity_emoji = {"high": "🔥", "medium": "⚡", "low": "💡"}.get(trigger.get('severity', 'low'), '💡')
st.write(f"{severity_emoji} {trigger.get('description', 'Unknown trigger')}")
with col2:
contacts = company.get('contacts', [])
if contacts:
st.write("**👥 Decision Makers:**")
for contact in contacts:
confidence = contact.get('confidence_score', 0)
confidence_color = "🟢" if confidence >= 75 else "🟡" if confidence >= 50 else "🔴"
st.write(f"{confidence_color} **{contact.get('first_name', '')} {contact.get('last_name', '')}**")
st.write(f" {contact.get('title', 'Unknown title')}")
st.write(f" 📧 {contact.get('email', 'No email')}")
st.write(f" Confidence: {confidence}%")
message = contact.get('generated_message', {})
if message.get('subject'):
st.write(f" **Subject:** {message['subject']}")
if message.get('body'):
preview = message['body'][:100] + "..." if len(message['body']) > 100 else message['body']
st.write(f" **Preview:** {preview}")
st.write("---")
st.subheader("📥 Export & Actions")
col1, col2, col3 = st.columns(3)
with col1:
export_data = []
for company in results['companies']:
for contact in company.get('contacts', []):
export_data.append({
'Company': company.get('name', ''),
'Industry': company.get('industry', ''),
'Lead Grade': company.get('lead_grade', ''),
'Lead Score': company.get('lead_score', 0),
'Trigger Count': len(company.get('trigger_events', [])),
'Contact Name': f"{contact.get('first_name', '')} {contact.get('last_name', '')}",
'Title': contact.get('title', ''),
'Email': contact.get('email', ''),
'Confidence': contact.get('confidence_score', 0),
'Subject Line': contact.get('generated_message', {}).get('subject', ''),
'Message': contact.get('generated_message', {}).get('body', '')
})
if export_data:
df = pd.DataFrame(export_data)
csv = df.to_csv(index=False)
st.download_button(
label="📄 Download Full Report (CSV)",
data=csv,
file_name=f"ai_bdr_prospects_{datetime.now().strftime('%Y%m%d_%H%M')}.csv",
mime="text/csv",
use_container_width=True
)
with col2:
if st.button("🔄 Sync to HubSpot CRM", use_container_width=True):
if not os.getenv("HUBSPOT_API_KEY"):
st.warning("HubSpot API key required for CRM export")
else:
with st.spinner("Syncing to HubSpot..."):
pipeline_agent = create_pipeline_manager_agent()
new_crm_results = pipeline_agent.tools[1]._run(results['companies'], min_lead_grade)
st.session_state.workflow_results['crm_results'] = new_crm_results
st.rerun()
with col3:
if st.button("🗑️ Clear Results", use_container_width=True):
st.session_state.workflow_results = None
st.rerun()
if __name__ == "__main__":
passThe Streamlit orchestration system coordinates all agents in an efficient workflow with real-time progress tracking and customizable settings. It offers clear result displays with metrics, detailed company information, and export options. The interface makes complex multi-agent operations easy to manage through an intuitive dashboard that sales teams can use without technical skills.
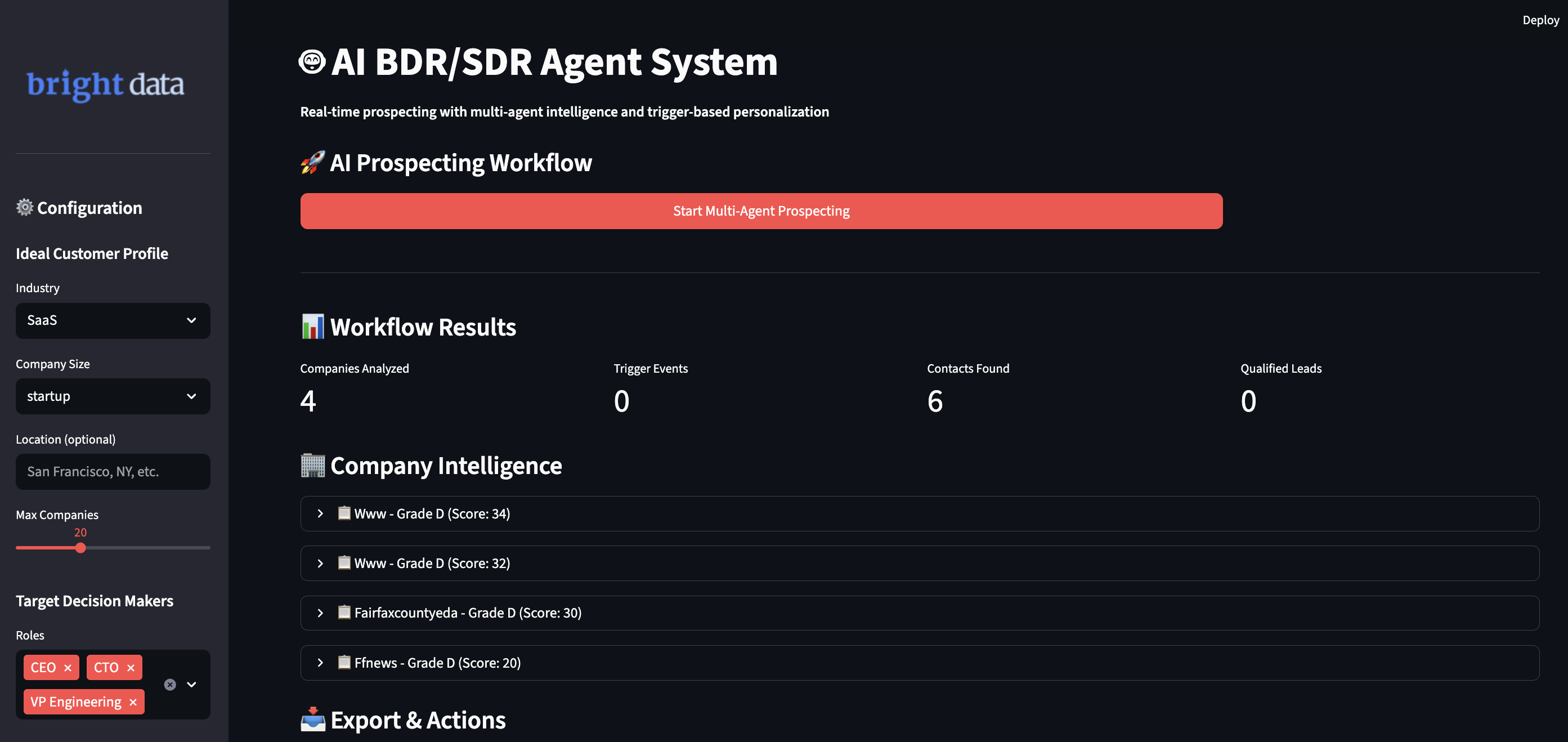
Running Your AI BDR System
Run the application to start intelligent prospecting workflows. Open your terminal and go to your project directory.
streamlit run ai_bdr_system.py
You will see the system’s smart workflow as it handles your requirements:
- It finds companies that match your ideal customer profile using real-time data checks.
- It tracks trigger events from various sources to find the best timing.
- It looks up decision-maker contacts using multiple sources and scores for reliability.
- It creates personalized messages that mention specific business insights.
- It scores leads automatically and adds qualified prospects to your CRM pipeline.
Final Thoughts
This AI BDR system shows how automation can streamline prospecting and lead qualification. To further enhance your sales pipeline, consider Bright Data products like our LinkedIn Dataset for accurate contact and company data, as well as other datasets and automation tools built for BDR and sales teams.
Explore more solutions in the Bright Data documentation.
Create a free Bright Data account to start building your automated BDR workflows.

Technical Writer
Arindam Majumder is a developer advocate, YouTuber, and technical writer who simplifies LLMs, agent workflows, and AI content for 5,000+ followers.





