

In modern data projects, data mapping aligns fields and records across systems so information keeps its meaning as it moves between databases and applications. Once manual and brittle, it now benefits from AI. In this guide, we’ll explore how AI transforms data mapping, the key techniques behind it, and how to turn public web data into analysis-ready datasets.
What is data mapping and why is it challenging?
Data mapping simply tells systems how data fields correspond. For example, a customer’s email in one database maps to email address in another. Without proper mapping, data transferred between systems can lose context or cause duplicates. Mapping is essential for integration, migration, and analytics: it helps ensure that when you move data into a new tool or warehouse, every value ends up in the right place.
However, traditional mapping is slow and prone to errors. In large enterprises, data lives in hundreds of different sources and formats. Teams often need to write custom scripts or use complex ETL tools, manually matching each field. This method doesn’t scale: projects can take months, and human errors are common.
The challenge becomes even greater when working with web data – unstructured HTML pages, inconsistent field naming, and messy formatting create additional complexity. Poor-quality source data leads to poor mapping results, regardless of how advanced your AI tools are.
How AI transforms data mapping
AI-powered data mapping uses machine learning and natural language processing to analyze source and target schemas, interpret field names and context, and learn from previous mappings to propose accurate matches instead of requiring manual field coding.
AI recognizes that cust_ID, customerID, and customer_id represent the same concept. Platforms detect data-type cues and suggest target fields accordingly, reducing mapping tasks from hours to minutes.
Here are the key benefits of AI data mapping:
- Speed and efficiency. Automation handles repetitive mapping and transformation setup, reducing manual effort.
- Accuracy and learning. Systems learn from your accept/reject choices, improving suggestions over time.
- Scalability. AI mapping handles large, complex datasets. As data volume and variety grow, modern tools can simultaneously analyze multiple schemas and sources.
- Adaptability. Unlike static scripts, AI mapping adapts to changes. When new fields or formats appear, AI infers relationships from context or user feedback. The system learns your organization’s data patterns, requiring less human correction over time.
- Better data quality and governance. Automated mapping helps enforce consistency and governance. By documenting how fields align, AI tools maintain data lineage and support compliance by tracking sensitive data routing.
- Lower costs. These benefits reduce costs through less manual labor, fewer errors requiring rework, and faster project completion.
Technologies behind AI data mapping
Several AI techniques power modern data mapping:
- Natural language processing (NLP). NLP interprets the meaning of field names and labels (e.g., Email Address vs e-mail) and can process documentation to extract context, making mapping more robust even when names differ widely.
- Machine learning models. ML models classify and predict mappings based on learned patterns. Each past mapping feeds the model: if many datasets show account_manager mapping to sales_rep in a billing system, the model will prioritize that suggestion next time – improving recommendations over time with a human in the loop.
- Knowledge graphs. Some platforms maintain internal knowledge graphs linking entities and relationships across systems. A graph can represent that a Customer ID in one system is the same as an Account Number in another, and that both relate to a Billing Reference, helping infer indirect mappings and keep schemas consistent.
- Deep learning and computer vision. For unstructured or semi-structured documents (e.g., PDFs, scanned forms), deep learning can extract text, tables, and key-value pairs so you can map them to structured targets.
- Semantic matching and schema alignment. Modern tools integrate schema-matching algorithms (including graph/ontology alignment) that combine lexical, structural, and instance-based evidence, plus domain dictionaries where available, to find correspondences.
How AI data mapping works (step by step)
AI data-mapping tools follow this workflow:
- Connect data sources. The tool connects to your source and target systems (databases, files, APIs), inspects field names, data types, sample values, and metadata, and uses NLP to read labels/descriptions so it understands context before proposing matches.
- Analyze and propose matches. It applies auto-mapping by name/position and semantic similarity to generate candidate pairs, often with confidence scores. For example, it may map country_code with CountryID. If it detects a type mismatch (text like “Qty: 12” vs. a numeric target), it will propose a parse/cast transformation before final mapping.
- Review and refine. High-confidence matches can be auto-accepted while ambiguous ones are flagged for steward review. Accept/reject actions are captured for audit and used to improve future suggestions.
- AI learns from feedback. The system internalizes your choices (your institutional memory), so similar datasets map faster next time and recommendations align with your naming conventions and policies.
- Deploy transformations. Once mappings are approved, the platform generates and operationalizes the required transformations (casts, concatenations, standardizations) and runs them inside managed ETL/ELT pipelines with scheduling, monitoring, and lineage capture.
Getting mapping-ready data from the web
Before AI can effectively map your data, you need clean, structured inputs. Web data often comes messy – inconsistent formatting, nested HTML, changing page structures. This is where proper web data collection becomes crucial for successful mapping projects.
Bright Data provides a platform to extract and prepare web data for AI, so mapping starts from cleaner inputs:
- AI Web Scraper. Identify page structure and extract structured data from modern sites; deliver JSON/CSV via API or webhooks.
- Datasets (pre-built). Ready-made, refreshed datasets with documented schemas (e.g., Amazon products), so field names and types are consistent out of the box.
- Proxy and Web Unlocker. Reliable access to public websites by handling blocks and CAPTCHAs – so you can collect the data before mapping, even on difficult sites.
- Browser API and Serverless Functions. Run programmable, hosted scraping workflows for multi-step collection prior to mapping.
- Integrations. Connect scraped or dataset outputs to AI app frameworks (e.g., LangChain, LlamaIndex) or your storage targets.
By handling collection and initial structuring, Bright Data lets you focus on mapping and transformation.
Simple example – mapping an Amazon product dataset
Let’s walk through a practical example using Amazon product data. Rather than scraping messy product pages manually, we’ll use Bright Data’s Amazon Product Dataset which provides clean, structured records perfect for AI mapping.
The dataset includes fields like title, brand, initial_price, currency, and availability. A sample record looks like:
{
"title": "Hanes Girls' Cami Tops, 100% Cotton Camisoles…",
"brand": "Hanes Girls 7-16 Underwear",
"initial_price": 10.00,
"currency": "USD",
"availability": true
}Suppose our target analytics schema needs ProductName, Brand, PriceUSD, and InStock. The AI mapping tool would propose these transformations:
- title → ProductName (high confidence semantic match)
- brand → Brand (exact name match)
- initial_price + currency → PriceUSD (combine fields, normalize to USD)
- availability → InStock (boolean conversion)
After mapping and transformation:
{
"ProductName": "Hanes Girls' Cami Tops, …",
"Brand": "Hanes Girls 7-16 Underwear",
"PriceUSD": 10.00,
"InStock": true
}The AI mapping tool automatically proposed most alignments because the source data was clean and consistently formatted.
For custom requirements, you could use the AI Web Scraper to extract specific Amazon fields into your preferred format, then map those to your target schema.
Note – Keep humans in the loop. AI mapping works best as an intelligent assistant, not a replacement for data expertise. Always validate critical mappings, especially for sensitive fields or regulatory compliance.
Advanced mapping with natural language queries
Sometimes you need to research and map data that doesn’t exist in pre-built formats. Bright Data’s Deep Lookup lets you generate custom datasets using natural language queries, then map the results to your target schema. For example:
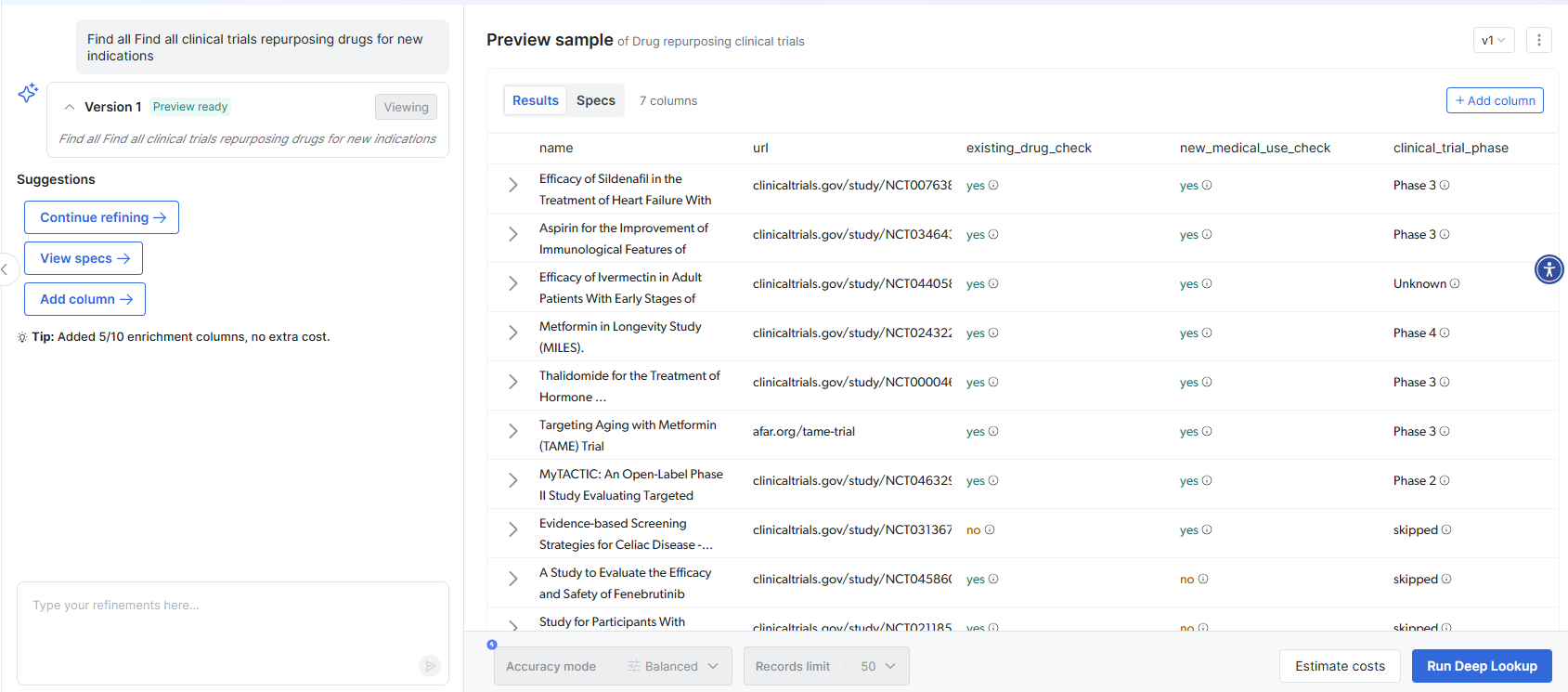
Deep Lookup scours web data to find matching companies and returns structured results ready for mapping:
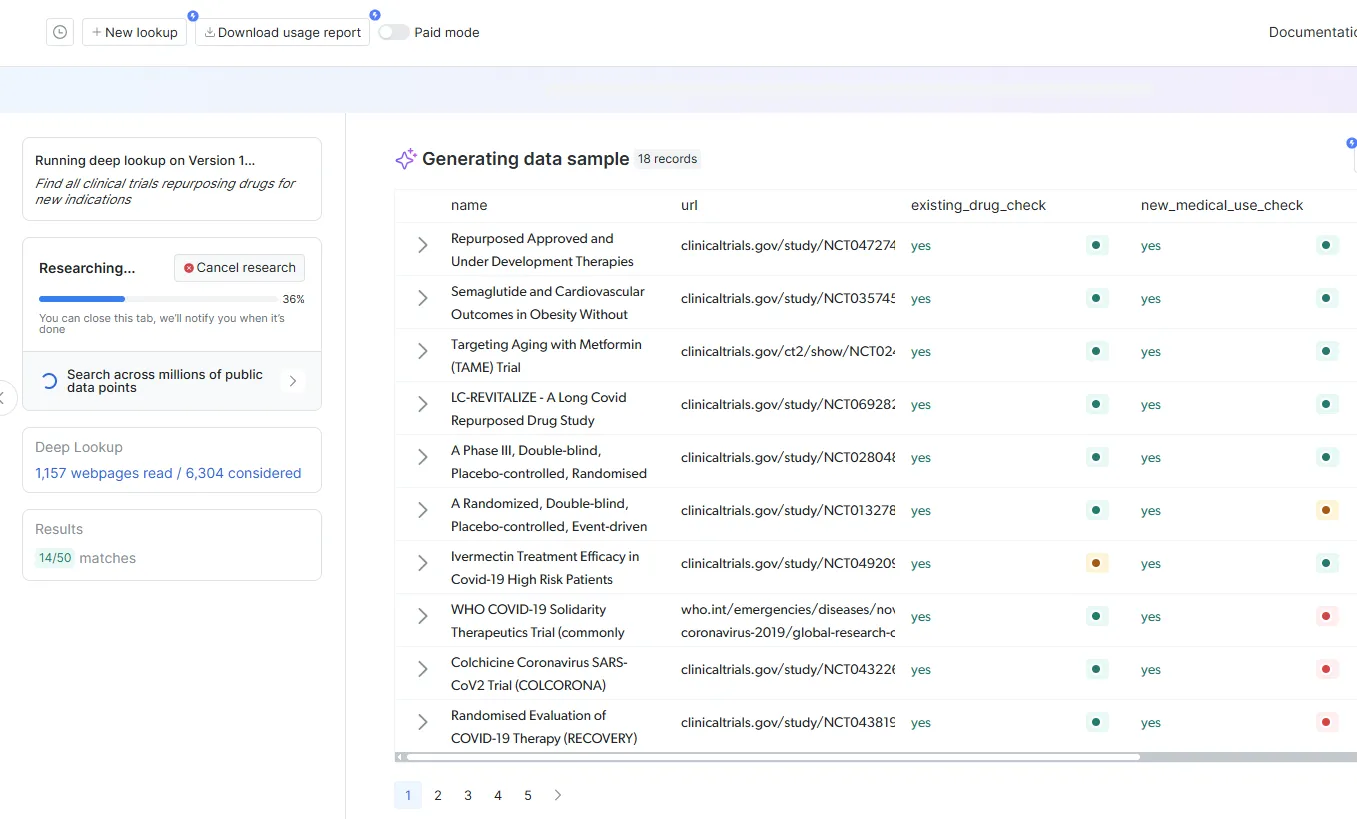
This eliminates the traditional research-then-structure-then-map workflow by delivering mapping-ready data directly from natural language queries.
Conclusion
AI data mapping is transforming how organizations integrate public web data into analytics and AI workflows. Success starts before mapping – high-quality, well-structured source data improves mapping accuracy and reduces manual intervention.
Bright Data’s solutions handle collection and structuring, so you can focus on mapping web data to your specific business needs and analytical frameworks.
Ready to see the impact of clean web data on your mapping projects? Contact us to get structured, mapping-ready datasets quickly.

Technical Writer
Satyam Tripathi helps SaaS and data startups turn complex tech into actionable content, boosting developer adoption and user understanding.



