

Crunchbase is the go-to source for company, funding, and investor data, and one of the hardest sites on the web to scrape: every page sits behind a Cloudflare challenge, and in 2026 that data increasingly feeds deal-sourcing models, CRM enrichment, and AI agents. This guide shows five ways to get it, with real, tested code and live output for each.
What this guide covers
- The five ways to pull Crunchbase data in 2026, and when to use each
- A manual Python attempt, and the Cloudflare wall it hits
- Web Unlocker in async mode for pages with no pre-built scraper
- The Scraping Browser when you need to click or paginate
- The Crunchbase Scraper API for clean, structured company JSON
- The ready-made Crunchbase dataset for bulk firmographics
- Feeding Crunchbase data to an AI agent over the Web MCP
Ready to skip the build? Pull a company now with the Crunchbase Scraper API, download a ready-made Crunchbase dataset, or start free with 5,000 records a month and no credit card.
What Crunchbase data is worth collecting
A Crunchbase company profile is dense firmographic data. The fields most teams want:
- Company: name, description, Crunchbase rank, type, website, HQ region and country
- Traction: monthly visits, number of investors, operating and IPO status
- People: founders and headcount range
- Signals: industries, social links, and similar companies
The Scraper API returns 98 of these fields per company as clean JSON. Note one thing up front: Crunchbase is so heavily protected that off-the-shelf screenshot services get blocked outright, yet Bright Data’s own Scraping Browser renders the live profile cleanly (Approach 3 shows the real captures). That gap is exactly why managed collection matters here.
Common use cases: VC and M&A deal sourcing, competitive and market intelligence, CRM and lead enrichment, and feeding structured company data to AI and RAG pipelines.
The five approaches at a glance
| Approach | Effort | Scale | Cost | Maintenance | Best for |
|---|---|---|---|---|---|
| Manual Python | High | None | Free (but blocked) | High | Learning why it is hard |
| Web Unlocker (async) | Medium | Medium | Per successful request | Medium | Custom pages, you control parsing |
| Scraping Browser | Medium | Medium | Pay per browser time | Medium | Interaction: clicks, pagination, etc. |
| Crunchbase Scraper API | Low | High | From $0.70 / 1K records | None | Structured company data at any volume |
| Crunchbase Dataset | None | Bulk | From $0.0025 / record | None | Market-wide firmographics, no code |
Approach 1: Manual scraping, and the Cloudflare wall
The naive attempt is one line. It does not work.
import requests
url = "https://www.crunchbase.com/organization/openai"
resp = requests.get(url, headers={"User-Agent": "Mozilla/5.0"}, timeout=30)
print("status:", resp.status_code)
print("cloudflare challenge:", "attention required" in resp.text.lower())The real output:
status: 403
cloudflare challenge: True
Crunchbase returns a 403 “Attention Required” Cloudflare challenge with no company data. Unlike some sites, this is not intermittent: a default request is blocked every time. Getting through reliably needs managed unblocking (rotating residential proxies, a real browser fingerprint, and automated challenge solving). If you want the DIY route anyway, our Python web scraping guide covers the fundamentals. The managed approaches that follow remove that burden.
Approach 2: Web Unlocker in async mode
When you need the raw page (for example a profile type with no pre-built scraper), Web Unlocker handles the Cloudflare challenge and returns the rendered HTML. Crunchbase is heavy enough that a synchronous unlock can exceed the request timeout, so use the async flow: submit, then poll.
import os
import time
import requests
HEAD = {"Authorization": f"Bearer {os.environ['BRIGHTDATA_API_KEY']}"}
ZONE = os.environ["BRIGHTDATA_UNLOCKER_ZONE"]
# 1. Submit (async: returns immediately with a response_id)
rid = requests.post(
"https://api.brightdata.com/unblocker/req",
params={"zone": ZONE}, headers=HEAD,
json={"url": "https://www.crunchbase.com/organization/openai"},
).json()["response_id"]
# 2. Poll until the unlock completes
while True:
r = requests.get(
"https://api.brightdata.com/unblocker/get_result",
params={"response_id": rid}, headers=HEAD,
)
if r.status_code == 200:
html = r.text
break
time.sleep(10)
print(len(html), "bytes")This returned the full OpenAI profile (about 1.08 MB) in roughly 63 seconds, where a synchronous call timed out past 280 seconds. The company data sits in the page’s embedded JSON, so you extract fields directly:
import re
title = re.search(r"<title>(.*?)</title>", html).group(1)
desc = re.search(r'"short_description":"([^"]+)"', html).group(1)
print(title)
print(desc[:70])Real output:
OpenAI - Crunchbase Company Profile & Funding
OpenAI is an AI research and deployment company that develops advancedYou own the parsing, which is the right trade-off for a page type with no pre-built scraper.
Web Unlocker is also exposed through the Web MCP: its scrape_as_markdown tool runs on Web Unlocker, so an AI agent can unlock a page straight from a plain-language request, with no API wiring on your side. The same call works from the terminal.
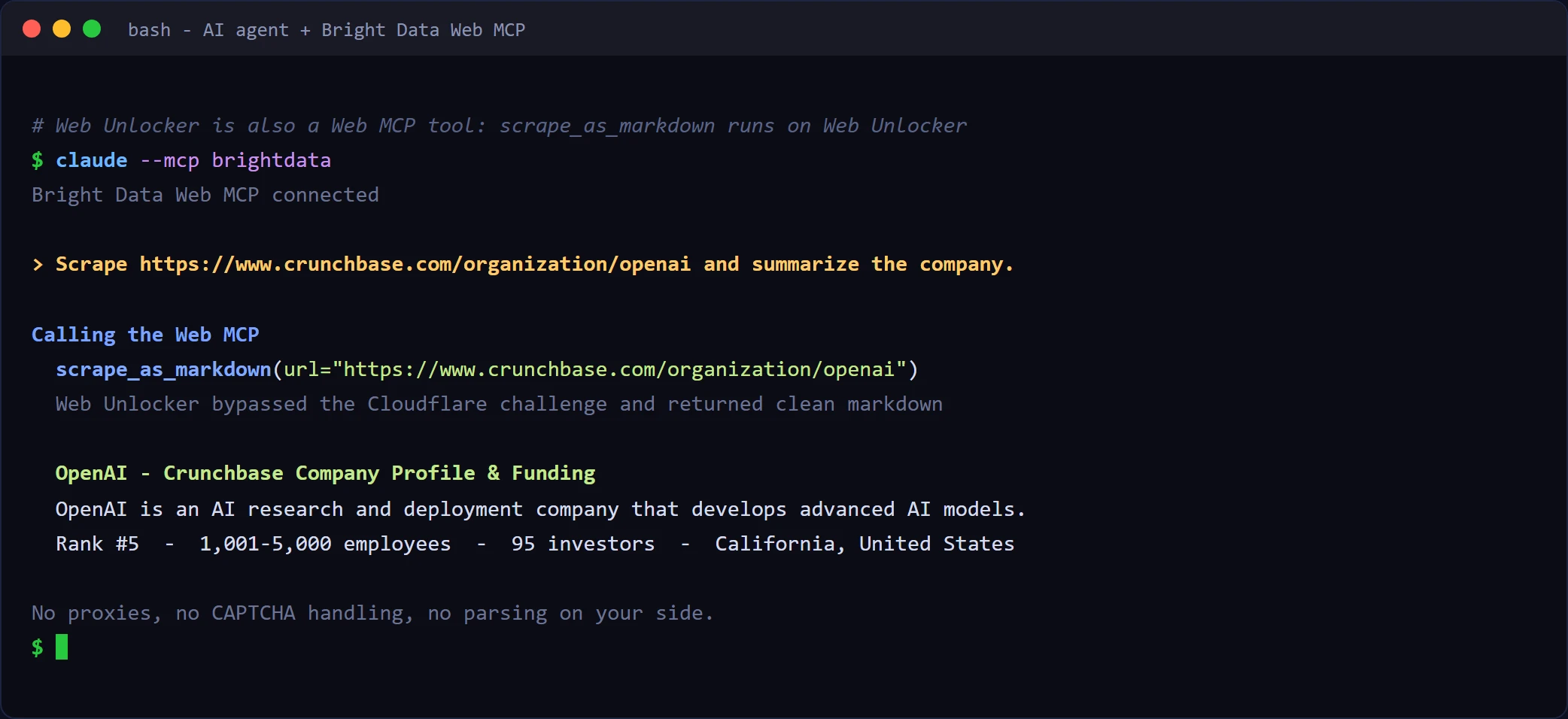
If all you want is clean company data, the Scraper API removes that step.
Approach 3: When you need a real browser, the Scraping Browser
The approaches so far fetch a page. Sometimes you need to interact with it first: Click through to a funding-rounds tab, dismiss a modal, or paginate a search result before the data you want even loads. That is what the Scraping Browser is for, a managed Chrome instance in the cloud with the same unblocking built in, driven over the standard Chrome DevTools Protocol (CDP). Because it is a real browser, it renders Crunchbase’s JavaScript and clears the Cloudflare challenge that stopped Approach 1, and because it speaks CDP it drops into an existing Playwright or Puppeteer script with a one-line endpoint swap.
The quickest way to see it work is the Bright Data CLI, which drives a Scraping Browser session for you. Open OpenAI’s profile, then screenshot the full page:
brightdata browser open https://www.crunchbase.com/organization/openai --zone scraping_browser2
brightdata browser screenshot --full-pageThe session is live and the page renders in full, the same profile that returns a 403 to a plain request:
Navigated to https://www.crunchbase.com/organization/openai
Title: OpenAI - Crunchbase Company Profile & Funding
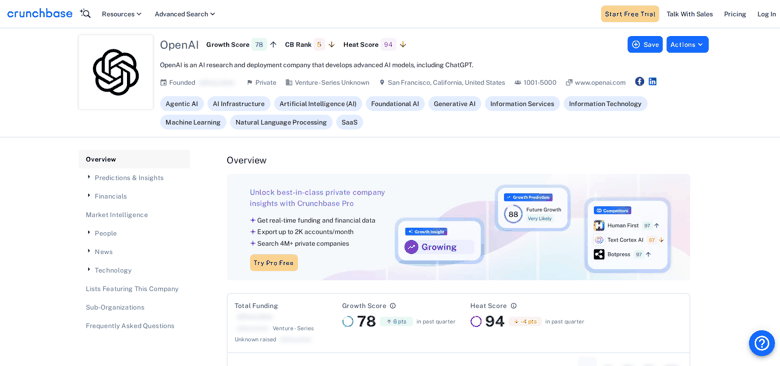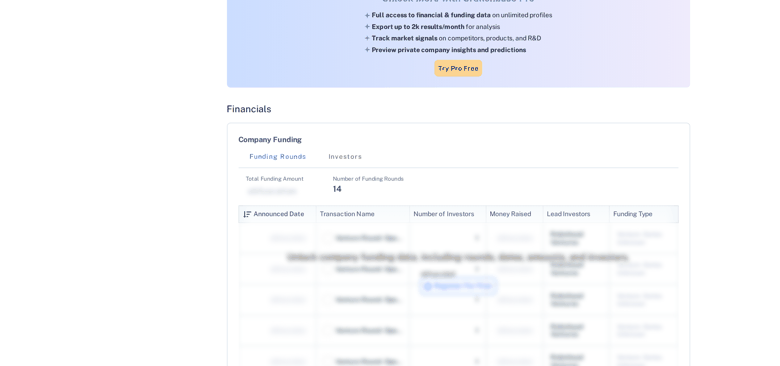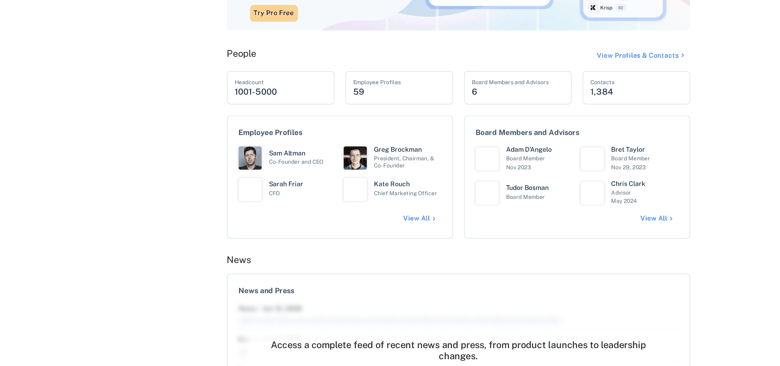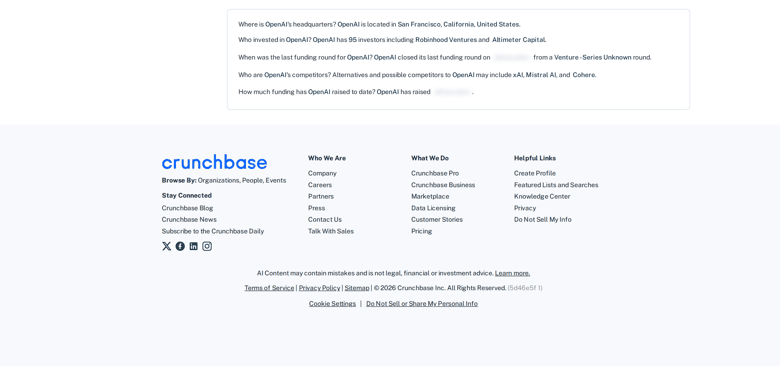
URL: https://www.crunchbase.com/organization/openaiHere is that rendered profile, with the firmographic blocks the page exposes numbered:
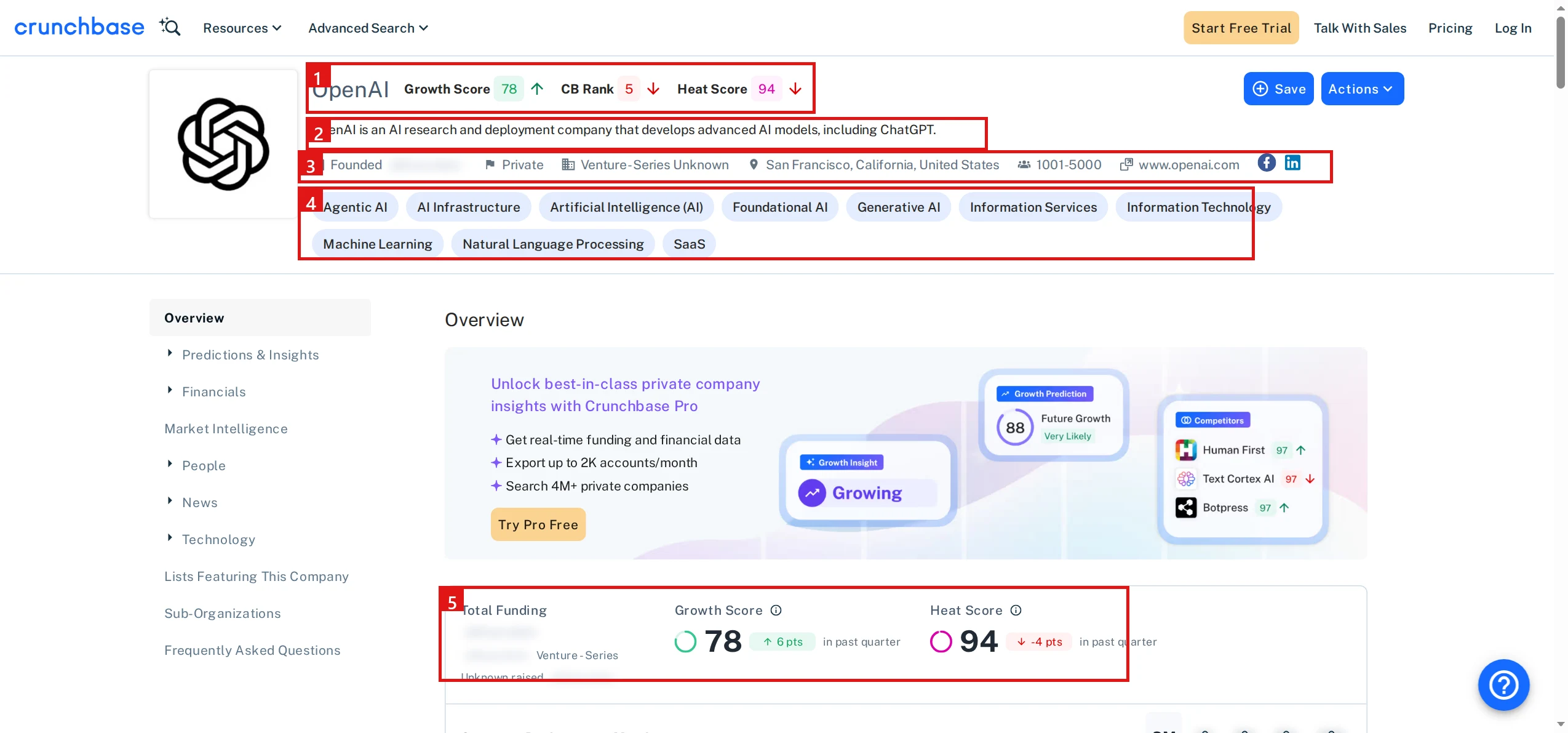
- Company name and Crunchbase rank (CB Rank 5 for OpenAI)
- Description of what the company does
- Headquarters, company size, type, and website
- Industries the company operates in
- Funding totals and Crunchbase scores
The session stays open between commands, so follow-ups act on the same page with no re-navigation:
brightdata browser snapshot # accessibility tree of the live page
brightdata browser screenshot --full-pageA full-page capture shows how much a real browser pulls in that a single fetch would miss, funding rounds, investors, similar companies, and news, all rendered:
In code, you connect a normal Playwright script to the cloud browser over CDP, with no local Chrome and no driver to manage:
import time
from playwright.sync_api import sync_playwright
# wss endpoint from your Scraping Browser zone in the Bright Data dashboard
CDP = "wss://brd-customer-<id>-zone-<zone>:<password>@brd.superproxy.io:9222"
with sync_playwright() as p:
browser = p.chromium.connect_over_cdp(CDP)
page = browser.new_page()
page.goto("https://www.crunchbase.com/organization/openai",
timeout=120_000, wait_until="domcontentloaded")
# the Scraping Browser clears the Cloudflare challenge; wait for the real page
for _ in range(12):
if "moment" not in page.title().lower():
break
time.sleep(5)
print(page.title()) # OpenAI - Crunchbase Company Profile & Funding
# interact first if needed (click a tab, paginate, etc.), then read the DOM
print(page.locator("identifier-formatter span").first.inner_text()) # OpenAI
browser.close()One caveat: the Scraping Browser is metered by browser time, not per delivered record, so it is not the cheapest way to pull a single profile (the Scraper API in the next approach is). Reach for it when the job genuinely needs interaction, a click path, scrolling, or pagination a one-shot fetch cannot do. It is also available in the Web MCP’s Pro mode, so an AI agent can drive the same browser.
Approach 4: The Crunchbase Scraper API
The Crunchbase Scraper API is a pre-built scraper. You send company URLs and receive structured JSON, with the Cloudflare unblocking handled server-side. It is part of Bright Data’s Web Scraper API, which covers 700+ sites.
For up to 20 URLs, use the synchronous endpoint:
import os
import requests
DATASET_ID = "gd_l1vijqt9jfj7olije" # Crunchbase companies information
TOKEN = os.environ["BRIGHTDATA_API_KEY"]
resp = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": DATASET_ID, "format": "json"},
headers={"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"},
json={"input": [{"url": "https://www.crunchbase.com/organization/openai"}]},
timeout=200,
)
company = resp.json()[0]
for field in ("name", "about", "num_employees", "region", "country_code",
"cb_rank", "num_investors", "monthly_visits", "operating_status", "ipo_status"):
print(f"{field}: {company[field]}")The real response is a clean record with 98 fields (the full record also includes 11 founders, 10 industries, and social links). Trimmed output for this company:
name: OpenAI
about: OpenAI is an AI research and deployment company that develops advanced AI models
num_employees: 1001-5000
region: California
country_code: United States
cb_rank: 5
num_investors: 95
monthly_visits: 487467460
operating_status: active
ipo_status: privateNo proxies, no Cloudflare handling, no parsing. For larger jobs switch to the asynchronous endpoint: trigger a collection, poll for completion, then download.
import os
import time
import requests
DATASET_ID = "gd_l1vijqt9jfj7olije"
HEAD = {"Authorization": f"Bearer {os.environ['BRIGHTDATA_API_KEY']}", "Content-Type": "application/json"}
companies = [
"https://www.crunchbase.com/organization/openai",
"https://www.crunchbase.com/organization/anthropic",
# ... hundreds more
]
snap = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
params={"dataset_id": DATASET_ID, "format": "json"}, headers=HEAD,
json={"input": [{"url": u} for u in companies]},
).json()["snapshot_id"]
while True:
status = requests.get(
f"https://api.brightdata.com/datasets/v3/progress/{snap}", headers=HEAD,
).json()["status"]
if status == "ready":
break
time.sleep(10)
data = requests.get(
f"https://api.brightdata.com/datasets/v3/snapshot/{snap}",
params={"format": "json"}, headers=HEAD,
).json()
print(len(data), "companies collected")You only pay for delivered records, the Web Scraper API starts from $0.70 per 1,000 records, and every new account gets 5,000 free records per month to test with, no credit card required. Two practical notes: each snapshot stays downloadable for 30 days, and custom_output_fields lets you trim the response to only the fields you need.
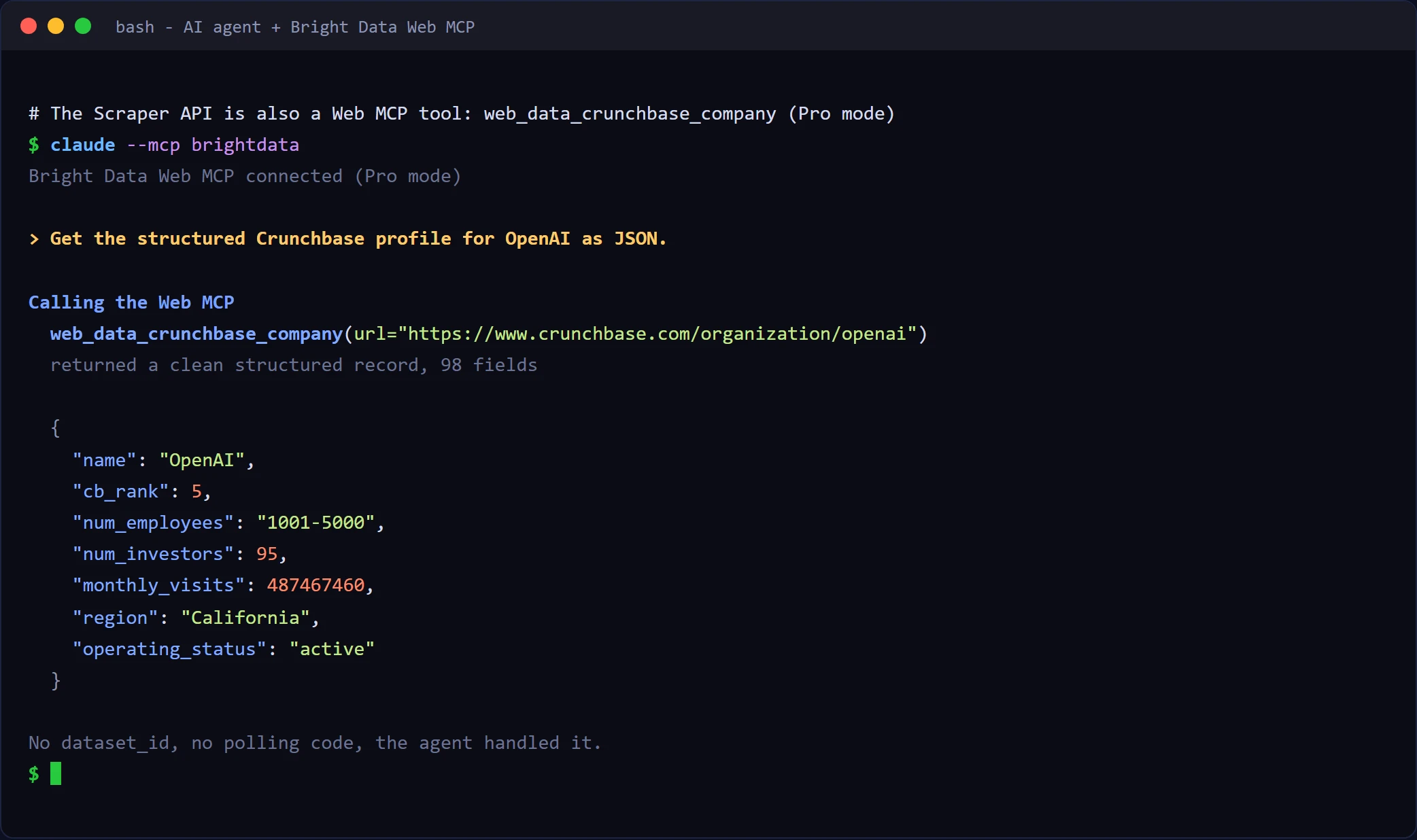
Prefer not to write any of this? The same scraper is exposed as a Web MCP tool, web_data_crunchbase_company (Pro mode), so an AI agent returns the identical 98-field record from a plain-language request, with no dataset_id and no polling code on your side. It runs the same from the terminal:
Approach 5: The ready-made Crunchbase dataset
If you need market-wide coverage rather than a specific list of companies, skip collection and buy the Crunchbase dataset. Same structured schema, pre-collected and refreshed.
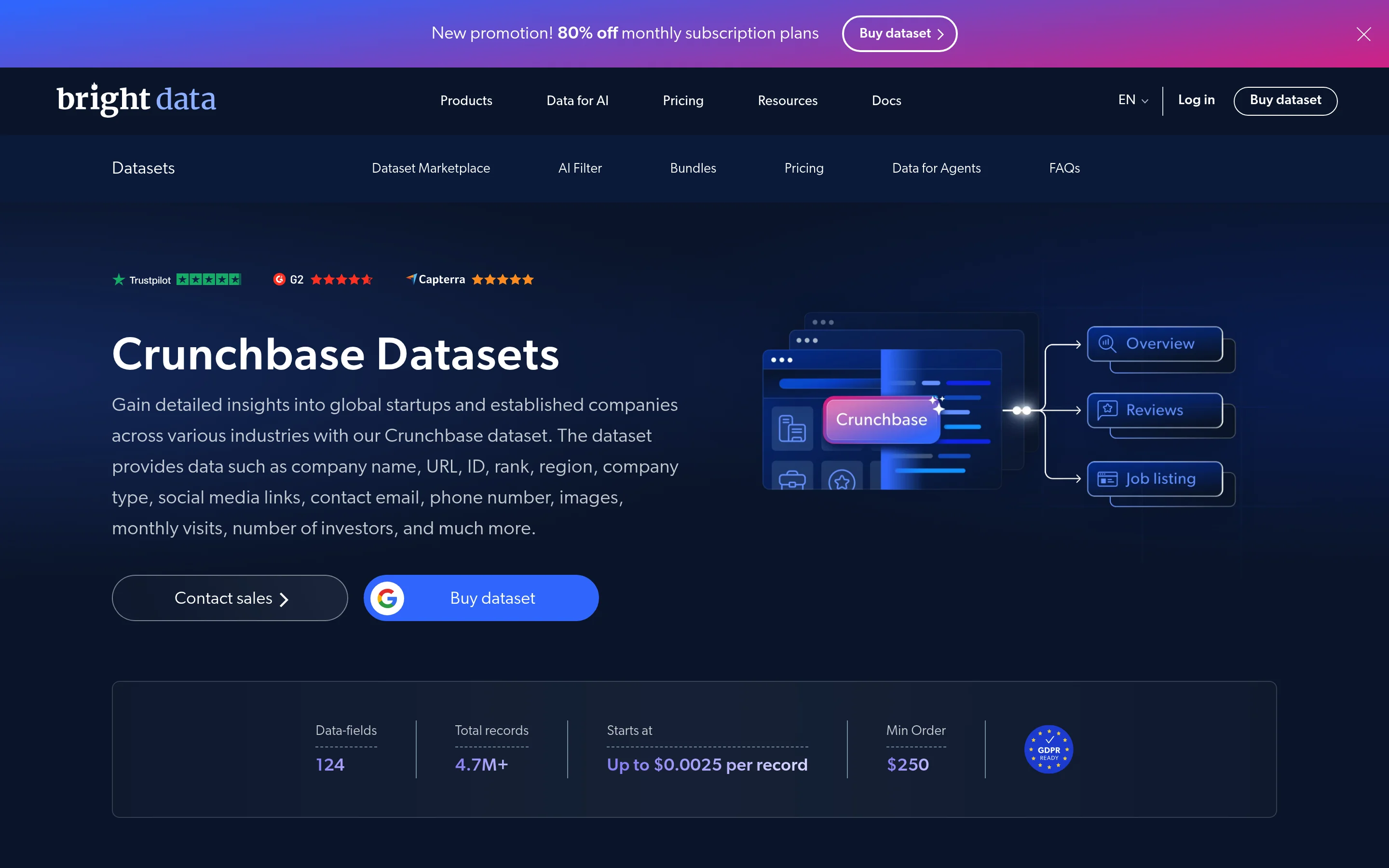
The marketplace dataset carries 4.7M+ company records across 124 fields, priced from $0.0025 per record with a $250 minimum order, GDPR-ready, as a one-time download or a refreshing subscription. You filter by region, industry, rank, or other attributes and download in JSON, CSV, or Parquet. Bright Data publishes the same ready-to-use data for adjacent needs too, including the best company data providers and best B2B data providers.
Bonus: feed Crunchbase data to an AI agent (MCP)
The biggest shift of 2026 is that the consumer of this data is often an AI agent. The Model Context Protocol (MCP) is how agents call external tools, and Bright Data’s Web MCP server gives any LLM live search (SERP API) and scraping through the same unblocking infrastructure, so the agent never hits the Cloudflare wall from Approach 1.
Point your MCP client at the hosted server with one line:
https://mcp.brightdata.com/mcp?token=YOUR_API_TOKENOr run it locally, or wire it into your coding agent with one command:
brightdata add mcp --agent claude-code,cursor,codexThe free Rapid mode exposes search_engine, scrape_as_markdown, and discover at one credit per request, from the same 5,000 free monthly credits. Pro mode adds 60+ structured tools, including pre-built web data extractors and Scraping Browser automation. For a full walkthrough, see the Web MCP scraping tutorial.
You can try the exact tools the agent uses from your terminal first, with the Bright Data CLI:
Once connected, you ask in plain language and the agent calls the tools itself, returning live company data with no scraping code in your project:
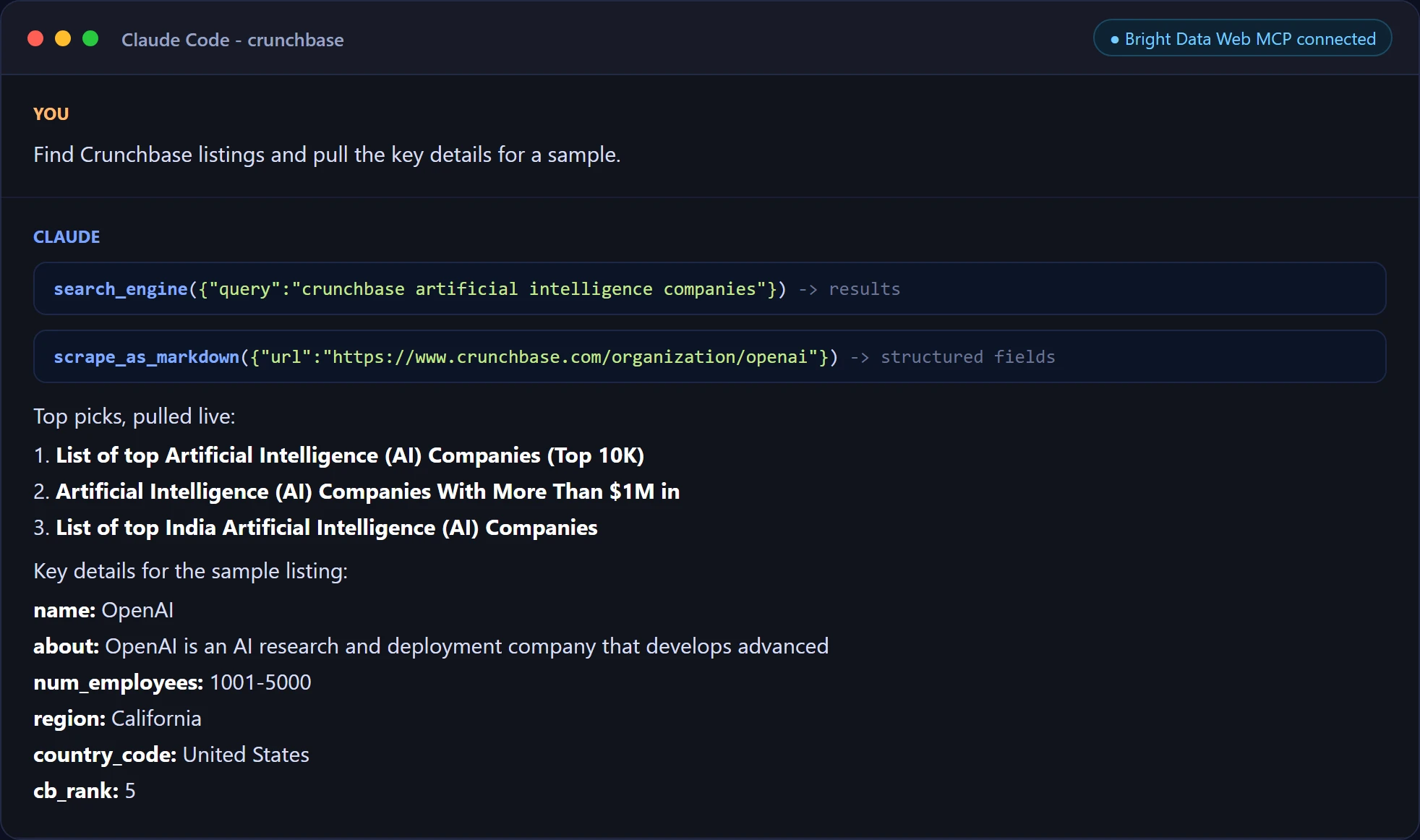
What you can do with the data
With records in hand, analysis is a few lines. Here we pull a handful of AI labs and rank them by investor count.
import requests
DATASET_ID = "gd_l1vijqt9jfj7olije"
companies = ["openai", "anthropic", "databricks", "mistral-ai", "hugging-face"]
resp = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={"dataset_id": DATASET_ID, "format": "json"},
headers={"Authorization": f"Bearer {TOKEN}", "Content-Type": "application/json"},
json={"input": [{"url": f"https://www.crunchbase.com/organization/{c}"} for c in companies]},
)
ranked = sorted(
(c for c in resp.json() if c.get("num_investors")),
key=lambda c: c["num_investors"], reverse=True,
)
for c in ranked:
print(c["name"], "-", c["num_investors"], "investors, rank", c["cb_rank"])Real output:
Anthropic - 133 investors, rank 94
OpenAI - 95 investors, rank 5
Databricks - 91 investors, rank 446
Mistral AI - 46 investors, rank 10
Hugging Face - 40 investors, rank 2425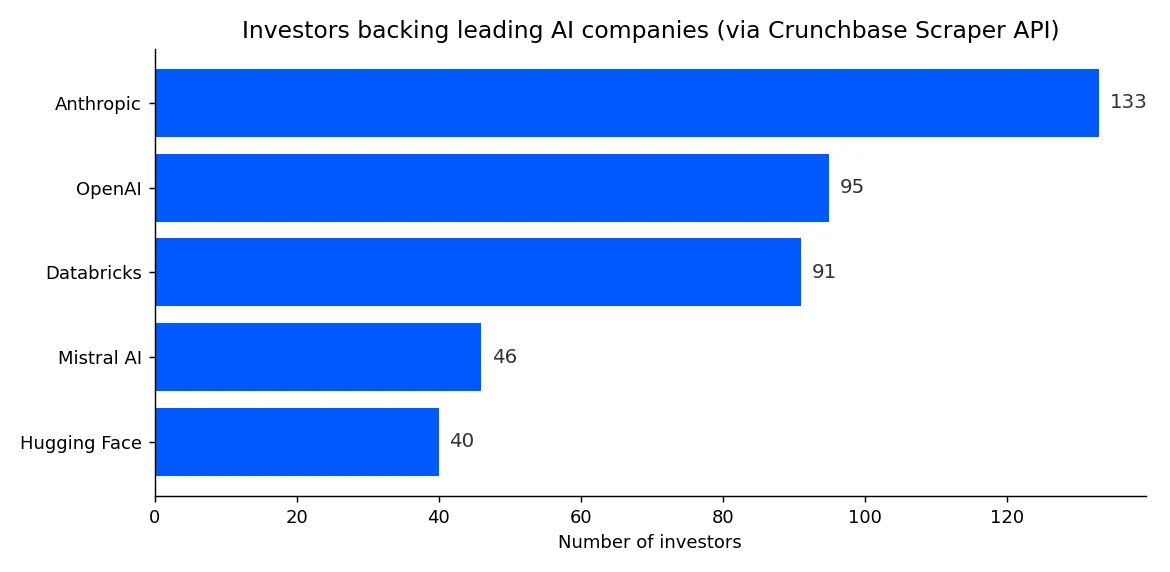
Anthropic has drawn the widest investor base of the group (133), ahead of OpenAI (95) and Databricks (91), while Crunchbase rank tells a different story, with OpenAI at #5 and Mistral AI at #10. One practical habit: validate that each slug resolves to the company you expect. A sixth lab in this run pointed at a stale org record (rank above 200,000, headcount 1 to 10) and was dropped before charting, the kind of check worth adding before you trust a batch.
How to choose
- Just learning? The manual attempt shows why Crunchbase is hard. Do not run it in production.
- Need a page with no pre-built scraper, and want to own parsing? Use Web Unlocker in async mode.
- Need to click, or paginate before the data loads? Use the Scraping Browser and drive it with Playwright over CDP.
- Need clean, structured company data at any volume? Use the Crunchbase Scraper API. This is the default.
- Need market-wide firmographics with no code? Use the dataset.
For head-to-head comparisons, see our roundups of the best Crunchbase data providers and the best company data providers.
Conclusion
Crunchbase is a worst-case scraping target: aggressive Cloudflare protection that blocks plain requests and even screenshot services. That makes the right level of abstraction matter more than clever code. Web Unlocker gets you the page when you need custom control, the Scraping Browser drives a real session when you need click through, the Scraper API gives you 98 structured fields per company with zero maintenance, and the dataset gives you 4.7M+ companies with no code at all. Start with the free monthly records on the Scraper API, point it at the companies you care about, and build from there.
Frequently Asked Questions
Can I scrape Crunchbase with plain Python requests?
No. Crunchbase fronts every page with a Cloudflare challenge, so a default request returns a 403 ‘Attention Required’ page with no data, every time. You need managed unblocking, which is why most teams use Web Unlocker or the Crunchbase Scraper API.
What data does the Crunchbase Scraper API return?
A single company record includes 98 fields: name, description, Crunchbase rank, headcount range, region and country, website, industries, operating and IPO status, founders, number of investors, social links, and more, as clean JSON with no parsing required.
Why use async mode for Web Unlocker on Crunchbase?
Crunchbase is heavy enough that a synchronous unlock can exceed the request timeout (over 280 seconds in testing). The async flow submits the URL, returns a response_id immediately, and you poll for the result, which came back in about 63 seconds.
Should I use the Scraper API or the ready-made dataset?
Use the Scraper API when you have specific company URLs and want fresh data on demand. Use the dataset when you need market-wide coverage without supplying URLs. The Crunchbase dataset carries 4.7M+ records across 124 fields and starts at $0.0025 per record.
How much does it cost to start?
Every new Bright Data account includes 5,000 free records per month across the Web Scraper API, Web Unlocker, and SERP API, with no credit card. Beyond that, the Web Scraper API starts from $0.70 per 1,000 delivered records.
Can an AI agent collect Crunchbase data through MCP?
Yes. Bright Data’s Web MCP server connects any MCP-compatible LLM (Claude, GPT, Gemini) to live web data. In the free Rapid mode the agent gets search_engine and scrape_as_markdown at one credit per request, so it can pull current company data on demand. Pro mode adds 60+ structured data tools.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.




