

Distributed web crawling is a strategy for scaling web scrapers across multiple machines, thereby overcoming the limitations of single-node crawlers. In this article, we’ll explore:
- Distributed web crawling vs single-node web crawling
- The core architecture of distributed web crawling
- Real world examples of distributed web crawling
- Implementation strategies and best practices
- Common pitfalls and how to fix them
TL;DR: Distributed web crawling uses a cluster of machines to crawl websites in parallel, solving scalability and speed challenges that single-node crawlers can’t handle. It provides higher throughput and reliability (no single bottleneck) at the cost of added architectural complexity and overhead.
Distributed vs Single-Node Crawling
Most crawling projects don’t need distributed systems, yet teams routinely waste months building complex distributed architectures when a single server would suffice.
In a single-node crawler, one machine handles all fetching, parsing, and storing. This kind of system is easier to develop and maintain, and it saves you money. It’s great for fetching 60-500 pages per minute, but as your crawling needs grow, a single node becomes a bottleneck because you’ll be limited by CPU, memory, and network constraints.
In contrast, distributed crawlers spread work across multiple nodes, enabling concurrent fetching at scale, high speed, and improved fault tolerance. If one worker crashes, others continue running, thereby improving reliability. The trade-off is that distributed systems require message queues, synchronization of a URL frontier, and careful design to avoid duplication or overwhelming target sites.
Comprehensive Comparison
| Aspect | Single-Node | Distributed |
|---|---|---|
| Performance | 4 seconds/page average, 60-120 pages/minute | 30x faster, 50,000+ requests/second |
| Scalability | Limited by single machine resources | Linear scaling across nodes |
| Fault Tolerance | Single point of failure | Automatic failover, self-healing |
| Geographic Distribution | Fixed location | Multi-region deployment |
| Resource Utilization | Vertical scaling only | Horizontal scaling optimized |
| Complexity | Simple setup, minimal overhead | Complex orchestration, higher operational cost |
| Cost | Lower initial investment | Higher infrastructure costs, better ROI at scale |
| Maintenance | Minimal operational burden | Requires distributed systems expertise |
| Data Processing | Local processing only | Parallel processing across nodes |
| Anti-Detection | Limited IP rotation | Advanced proxy management, fingerprinting |
Should You Go Distributed? (A Decision Tree)
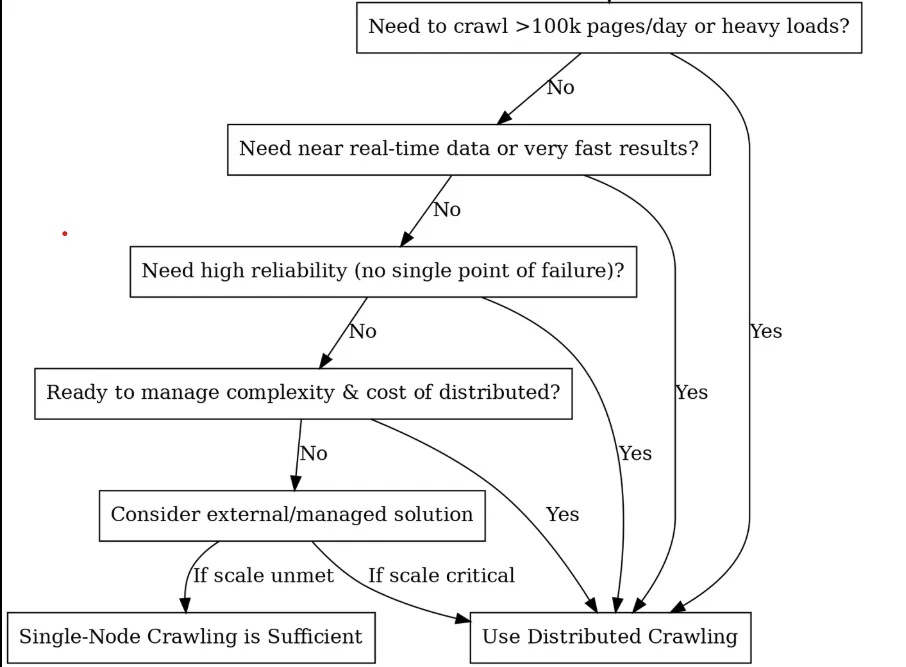
Core Building Blocks & Architecture
Once you’ve decided to go with distributed crawling, the next step is to break down what you’re actually building. Think of it like assembling a high-performance racing team where each component has a specific job, and they all need to work together seamlessly. Here are the key components you’d need to build a distributed crawling system:
Scheduler / Queue (The Brain)
At the heart of a distributed crawler is a scheduler or task queue that coordinates work among nodes, and it’s where your URLs live before they get crawled. A scheduler component may also handle politeness (timing) and retries. For instance, you might implement domain-specific queues to ensure one site isn’t hit by all workers at once.
With schedulers, you’ve got three main options, each with its own personality:
- Kafka: This is like the heavyweight champion. It’s built for massive throughput and doesn’t break a sweat handling millions of messages per second. The beauty lies in its log-based design, which is perfect for managing your URL frontier. You can partition by domain to keep your crawling polite.
- RabbitMQ: This is like a Swiss Army knife. More flexible routing than Kafka, with features like priority queues. RabbitMQ has in-memory storage, so it’s faster for smaller workloads. Great when you need different crawling strategies for different types of content.
- Celery: The Python developer’s best friend. This option is not as efficient as the others, but it’s easy to use. Celery is perfect for prototyping or medium-scale crawling when you need to get something working quickly.
URL Frontier & Deduplication: The Crawler’s Memory
Ever accidentally crawl the same page 1,000 times? That’s where deduplication saves you. You need to track what you’ve seen while respecting server politeness, so you don’t repeatedly hammer the same domain.
Redis Sets can give you perfect accuracy, but they eat a lot of memory. Bloom Filters use 90% less memory (1.2GB vs 12GB+ for a billion URLs) but occasionally have false positives (they might say you haven’t seen a URL when you have), so you might want to go with this Redis implementation:
class DistributedURLFrontier:
def __init__(self, redis_client):
self.redis = redis_client
def add_url(self, url, priority=0):
domain = urlparse(url).netloc
# Skip if already seen
if self.redis.sismember("seen_urls", url):
return
# Mark as seen and queue by domain
self.redis.sadd("seen_urls", url)
self.redis.lpush(f"queue:{domain}", url)
self.redis.zadd("priority_queue", {url: priority})
def get_next_url(self):
# Get highest priority URL
result = self.redis.zrevrange("priority_queue", 0, 0)
if not result:
return None
url = result[0]
domain = urlparse(url).netloc
# Respect crawl delay (1 second between requests per domain)
last_crawl = self.redis.get(f"last_crawl:{domain}")
if last_crawl and time.time() - float(last_crawl) < 1.0:
return None
# Remove from queues and update last crawl time
self.redis.zrem("priority_queue", url)
self.redis.rpop(f"queue:{domain}")
self.redis.set(f"last_crawl:{domain}", time.time())
return url
Worker Nodes (The Muscle)
Worker nodes are your crawling workhorses. They are the processes or machines that actually perform the crawling work, like fetching URLs and processing the content. Each worker runs identical crawling logic (e.g. the same Python script or application), but they operate in parallel on different URLs from the queue.
To get the best out of your workers, you need to keep them stateless, so that any state (visited URLs, results, etc.) is stored in shared storage or passed via messages. This way, any worker can grab any job, and when one dies, others instantly pick up the slack without missing a beat.
class DistributedWorker:
def __init__(self, worker_id, max_concurrent=50):
self.worker_id = worker_id
self.semaphore = asyncio.Semaphore(max_concurrent)
self.session = aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=30),
connector=aiohttp.TCPConnector(limit=100)
)
async def crawl_batch(self, urls):
tasks = [self.crawl_url(url) for url in urls]
return await asyncio.gather(*tasks, return_exceptions=True)
async def crawl_url(self, url):
async with self.semaphore:
try:
async with self.session.get(url) as response:
content = await response.text()
return {'url': url, 'content': content, 'status': response.status}
except Exception as e:
return {'url': url, 'error': str(e)}
Pro tip: With workers, it’s important not to use a sledgehammer for everything. You should use lightweight HTTP workers for static HTML and heavy Puppeteer workers for JavaScript-rendered pages. Different tools, different worker pools. You can easily choose the right proxy types for your worker fleet with our comprehensive proxy selection guide.
Storage Layer (The Warehouse)
The storage layer is where you save the crawled data and metadata, and it often consists of two parts:
- Content Storage handles the bulk raw HTML, JSON responses, images, PDFs. Think of it as your digital warehouse. Object stores like S3, Google Cloud Storage, or HDFS excel here because they scale infinitely and handle concurrent writes from multiple workers without breaking a sweat.
- Metadata Storage holds the structured gold you’ve extracted—parsed fields, entity relationships, crawl timestamps, and success/failure status. This goes into databases optimized for queries and updates, not just storage volume.
Distributed crawlers need storage that handles massive concurrent writes without choking. Object stores like S3 or Google Cloud Storage excel at raw content because they scale infinitely, while NoSQL databases (MongoDB, Cassandra) or SQL handle structured metadata effectively.
Monitoring & Alerting
Operating a distributed crawler requires visibility into the system’s performance. You can use Prometheus and Grafana to create comprehensive monitoring dashboards that track crawl rates, success rates, response times, and queue depths. Key metrics include requests per second by domain, 95th percentile response times, and queue size trends.
Anti-Bot & Evasion Layer
Web crawling at scale means constant cat-and-mouse games with anti-bot systems. You need three layers of defense: IP rotation across thousands of residential and datacenter proxies, fingerprint randomization of user agents and browser signatures, and behavioral mimicking to avoid detection patterns.
Bright Data Web Unlocker offers enterprise-grade anti-detection capabilities with a 99%+ success rate, achieved through automatic CAPTCHA solving, IP rotation, and browser fingerprinting. Its API-based approach simplifies integration while handling complex anti-bot challenges.
class BrightDataWebUnlocker:
def crawl_url(self, url: str, options: Dict = None) -> Dict:
payload = {
"url": url,
"zone": self.zone,
"format": "raw",
"country": "US",
"render_js": True,
"wait_for_selector": ".content"
}
response = requests.post(
self.base_url,
headers={"Authorization": f"Bearer {self.api_key}"},
json=payload,
timeout=60
)
Advanced proxy rotation implements health checking, geographic optimization, and failure recovery across residential, datacenter, and mobile proxy pools. Successful proxy management requires 1000+ IPs with intelligent rotation algorithms.
Fingerprinting avoidance randomizes user agents, browser fingerprints, and network characteristics to prevent detection by sophisticated anti-bot systems. This includes TLS fingerprint rotation, canvas fingerprinting spoofing, and behavioral pattern simulation.
Real-World Use Cases with Code Examples
Let’s explore two common use cases for distributed crawlers, and outline how one might implement them with code snippets. We’ll use Python and Celery in the examples for simplicity, but the principles apply generally.
Use Case 1: E-commerce Price Monitoring
Imagine you’re tracking competitor prices on 50,000 product pages every single day. If you try to use one machine to hit all those URLs, you’re looking at 12+ hours of crawling, assuming nothing breaks. Plus, most e-commerce sites will start blocking you after a few thousand rapid-fire requests from the same IP.
Here’s where distributed crawling helps. Instead of one overwhelmed machine, you spread those 50,000 URLs across dozens of workers, each using different IP addresses. What used to take half a day now finishes in 2-3 hours, and you fly under the radar of anti-bot systems.
The setup is straightforward. You need to maintain your competitor URL lists (grab them from sitemaps or discovery crawls), then use something like Celery with Redis to distribute the work. Each morning, you queue up all 50,000 URLs, and your worker army gets to work. Worker 1 handles Nike’s running shoes, Worker 2 tackles Adidas sneakers, Worker 3 grabs Puma pricing. All simultaneously, all from different IPs.
from celery import Celery
import requests
from bs4 import BeautifulSoup
import random
import time
import re
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# Initialize Celery app with Redis as broker
app = Celery('price_monitor', broker='redis://localhost:6379/0')
# Realistic user agents for rotation
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15"
]
# Proxy pool (replace with your actual proxy service)
PROXY_POOL = [
"<http://proxy1:8080>",
"<http://proxy2:8080>",
"<http://proxy3:8080>",
# Add your proxy endpoints here
]
def get_session_with_retries():
"""Create a session with retry strategy and random proxy."""
session = requests.Session()
# Retry strategy for resilience
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504],
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
# Random proxy rotation
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
@app.task(bind=True, max_retries=3)
def fetch_product_price(self, url, site_config=None):
"""Fetches product price with full anti-detection measures."""
# Human-like delay before starting
time.sleep(random.uniform(2, 8))
# Randomized headers to avoid fingerprinting
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Cache-Control": "max-age=0"
}
try:
session = get_session_with_retries()
resp = session.get(url, headers=headers, timeout=30)
resp.raise_for_status()
# Parse the page for price
soup = BeautifulSoup(resp.text, 'html.parser')
price_value = extract_price(soup, url, site_config)
if price_value:
# Store in database (implement your storage logic here)
store_price_data(url, price_value, resp.status_code)
return {"url": url, "price": price_value, "status": "success"}
else:
return {"url": url, "error": "Price not found", "status": "failed"}
except requests.exceptions.RequestException as e:
print(f"Request failed for {url}: {e}")
# Retry with exponential backoff
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"url": url, "error": str(e), "status": "failed"}
def extract_price(soup, url, site_config=None):
"""Extract price using multiple strategies."""
# Site-specific selectors (customize for each competitor)
price_selectors = [
".price", ".product-price", ".current-price", ".sale-price",
"[data-price]", ".price-current", ".price-now", ".offer-price"
]
# Try configured selectors first
if site_config and site_config.get('price_selector'):
price_selectors.insert(0, site_config['price_selector'])
price_text = None
for selector in price_selectors:
price_elem = soup.select_one(selector)
if price_elem:
price_text = price_elem.get_text(strip=True)
break
# Try data attributes as fallback
if not price_text:
price_elem = soup.find(attrs={"data-price": True})
if price_elem:
price_text = price_elem.get("data-price")
if not price_text:
return None
# Clean and parse price
return parse_price(price_text)
def parse_price(price_text):
"""Parse price from various formats."""
# Remove common currency symbols and whitespace
cleaned = re.sub(r'[^\\d.,]', '', price_text)
# Handle formats like "1,299.99" or "1299.99"
try:
# Remove commas and convert to float
if ',' in cleaned and '.' in cleaned:
# Format: 1,299.99
price_value = float(cleaned.replace(',', ''))
elif ',' in cleaned:
# Could be European format: 1299,99
if cleaned.count(',') == 1 and len(cleaned.split(',')[1]) == 2:
price_value = float(cleaned.replace(',', '.'))
else:
# Format: 1,299 (no cents)
price_value = float(cleaned.replace(',', ''))
else:
price_value = float(cleaned)
return price_value
except ValueError:
print(f"Could not parse price from: {price_text}")
return None
def store_price_data(url, price, status_code):
"""Store price data in your database."""
# Implement your storage logic here
# Could be PostgreSQL, MongoDB, or any other database
print(f"Storing: {url} -> ${price} (Status: {status_code})")
# Site-specific configurations for better accuracy
SITE_CONFIGS = {
"competitor1.com": {"price_selector": ".price-box .price"},
"competitor2.com": {"price_selector": "[data-testid='price']"},
"competitor3.com": {"price_selector": ".product-price-value"},
}
def get_site_config(url):
"""Get site-specific configuration."""
for domain, config in SITE_CONFIGS.items():
if domain in url:
return config
return None
# Load your 50k product URLs (from database, file, or API)
def load_product_urls():
"""Load URLs from your data source."""
# Replace with your actual data loading logic
urls = [
"<https://competitor1.com/product/123>",
"<https://competitor2.com/product/456>",
# ... 49,998 more URLs
]
return urls
# Main execution: dispatch all crawling tasks
def start_daily_price_monitoring():
"""Start the daily price monitoring job."""
product_urls = load_product_urls()
print(f"Starting crawl for {len(product_urls)} URLs...")
for url in product_urls:
site_config = get_site_config(url)
fetch_product_price.delay(url, site_config)
print("All tasks queued successfully!")
# Run with: python -m celery worker -A price_monitor --loglevel=info
# Start monitoring with: start_daily_price_monitoring()
In the enhanced code above, fetch_product_price is a robust Celery task designed for enterprise-scale price monitoring. By calling delay(url, site_config) for each URL, we queue tasks into Redis where 100+ workers can grab them instantly. The distributed approach transforms a 12-hour single-machine crawl into a 2-3 hour operation across your worker fleet.
Key production considerations:
- Proxy management is critical: This example includes a PROXY_POOL that rotates IPs per request, essential when hitting 50,000 URLs. Without this, you’re essentially DoS’ing target sites from one IP, guaranteeing blocks.
- Rate limiting per domain: Even with distribution, 50,000 URLs from one competitor site will trigger alarms if they all hit within minutes. We include human-like delays (
time.sleep(random.uniform(2, 8))), but consider domain-specific throttling. - Scheduling and monitoring. Use Celery Beat for daily scheduling or integrate with Airflow for complex workflows. The
start_daily_price_monitoring()function can be triggered via cron or your orchestration platform. - Data pipeline integration. After each crawl, the
store_price_data()function saves results to your database. - Failure resilience. The code includes retry logic with exponential backoff, but plan for partial failures. If 5% of URLs consistently fail, investigate whether those products were discontinued, moved, or if those specific sites have stronger anti-bot measures requiring different approaches.
Use Case 2: SEO and Market Research
SEO and market research require crawling millions of pages across two critical streams: content analysis and search engine monitoring. You’re not just scraping, you’re building competitive intelligence that demands speed, stealth, and precision.
If you want to track keyword mentions across 1 million competitor pages while simultaneously monitoring SERP rankings for hundreds of target keywords daily, a single machine would take weeks and get blocked within hours. This screams for a distributed architecture.
The distributed web crawling approach for this can be split into two streams:
- Content Intelligence: Crawl competitor sites, news outlets, and industry blogs to track keyword density, content gaps, and market trends
- SERP Surveillance: Monitor Google/Bing rankings for your target keywords, tracking competitor positions and SERP feature changes
from celery import Celery
import requests
from bs4 import BeautifulSoup
import redis
import hashlib
import json
import time
import random
import re
from urllib.parse import urljoin, urlparse
from dataclasses import dataclass
from typing import List, Dict, Optional
import logging
# Initialize Celery and Redis
app = Celery('seo_intelligence', broker='redis://localhost:6379/0')
redis_client = redis.Redis(host='localhost', port=6379, db=1)
# Anti-detection configurations
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 Chrome/120.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Safari/605.1.15"
]
PROXY_POOL = [
"<http://user:[email protected]:8080>",
"<http://user:[email protected]:8080>",
# Add your proxy endpoints
]
@dataclass
class KeywordData:
keyword: str
frequency: int
context: List[str] # Surrounding text snippets
url: str
domain: str
@dataclass
class SERPResult:
keyword: str
position: int
title: str
url: str
snippet: str
domain: str
class SEOCrawler:
def __init__(self):
self.session = self._create_session()
def _create_session(self):
session = requests.Session()
if PROXY_POOL:
proxy = random.choice(PROXY_POOL)
session.proxies = {"http": proxy, "https": proxy}
return session
def _get_headers(self):
return {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Cache-Control": "max-age=0"
}
# Deduplication utilities
def get_url_hash(url: str) -> str:
"""Generate consistent hash for URL deduplication."""
return hashlib.md5(url.encode()).hexdigest()
def is_url_processed(url: str) -> bool:
"""Check if URL was already processed today."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
return redis_client.exists(f"processed:{today}:{url_hash}")
def mark_url_processed(url: str):
"""Mark URL as processed with 24h expiry."""
url_hash = get_url_hash(url)
today = time.strftime("%Y-%m-%d")
redis_client.setex(f"processed:{today}:{url_hash}", 86400, 1)
# Stream 1: Content Intelligence Crawling
@app.task(bind=True, max_retries=3)
def crawl_content_for_keywords(self, url: str, target_keywords: List[str]):
"""Crawl a page and extract keyword intelligence."""
# Skip if already processed today
if is_url_processed(url):
return {"status": "skipped", "reason": "already_processed", "url": url}
# Human-like delay
time.sleep(random.uniform(3, 7))
try:
crawler = SEOCrawler()
response = crawler.session.get(
url,
headers=crawler._get_headers(),
timeout=30
)
response.raise_for_status()
# Extract content and analyze keywords
soup = BeautifulSoup(response.text, 'html.parser')
content_data = extract_keyword_intelligence(soup, url, target_keywords)
# Store results
store_keyword_data(content_data)
mark_url_processed(url)
return {
"status": "success",
"url": url,
"keywords_found": len(content_data),
"total_mentions": sum(kd.frequency for kd in content_data)
}
except Exception as e:
logging.error(f"Content crawl failed for {url}: {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=60 * (2 ** self.request.retries))
return {"status": "failed", "url": url, "error": str(e)}
def extract_keyword_intelligence(soup: BeautifulSoup, url: str, keywords: List[str]) -> List[KeywordData]:
"""Extract keyword data from page content."""
# Remove script and style elements
for script in soup(["script", "style", "nav", "footer", "header"]):
script.decompose()
# Get clean text content
text = soup.get_text()
text = re.sub(r'\\s+', ' ', text).strip().lower()
domain = urlparse(url).netloc
keyword_data = []
for keyword in keywords:
keyword_lower = keyword.lower()
# Find all occurrences
pattern = r'\\b' + re.escape(keyword_lower) + r'\\b'
matches = list(re.finditer(pattern, text))
if matches:
# Extract context around each match
contexts = []
for match in matches[:5]: # Limit to first 5 for performance
start = max(0, match.start() - 100)
end = min(len(text), match.end() + 100)
context = text[start:end].strip()
contexts.append(context)
keyword_data.append(KeywordData(
keyword=keyword,
frequency=len(matches),
context=contexts,
url=url,
domain=domain
))
return keyword_data
# Stream 2: SERP Tracking
@app.task(bind=True, max_retries=3)
def track_serp_rankings(self, keyword: str, search_engine: str = "google"):
"""Track SERP positions for a keyword."""
time.sleep(random.uniform(5, 10)) # Longer delay for search engines
try:
crawler = SEOCrawler()
if search_engine == "google":
search_url = f"<https://www.google.com/search?q={keyword}&num=20>"
else: # Bing
search_url = f"<https://www.bing.com/search?q={keyword}&count=20>"
# Special headers for search engines
headers = crawler._get_headers()
headers.update({
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Referer": "<https://www.google.com/>" if search_engine == "google" else "<https://www.bing.com/>"
})
response = crawler.session.get(search_url, headers=headers, timeout=30)
response.raise_for_status()
# Parse SERP results
soup = BeautifulSoup(response.text, 'html.parser')
serp_data = parse_serp_results(soup, keyword, search_engine)
# Store SERP data
store_serp_data(serp_data)
return {
"status": "success",
"keyword": keyword,
"results_found": len(serp_data),
"search_engine": search_engine
}
except Exception as e:
logging.error(f"SERP tracking failed for '{keyword}': {e}")
if self.request.retries < self.max_retries:
raise self.retry(countdown=120 * (2 ** self.request.retries))
return {"status": "failed", "keyword": keyword, "error": str(e)}
def parse_serp_results(soup: BeautifulSoup, keyword: str, search_engine: str) -> List[SERPResult]:
"""Parse search engine results page."""
results = []
position = 1
if search_engine == "google":
# Google result selectors
result_elements = soup.select('div.g')
for element in result_elements:
title_elem = element.select_one('h3')
link_elem = element.select_one('a[href]')
snippet_elem = element.select_one('.VwiC3b, .s3v9rd')
if title_elem and link_elem:
url = link_elem.get('href', '')
if url.startswith('/url?q='):
url = url.split('/url?q=')[1].split('&')[0]
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20: # Limit to top 20
break
else: # Bing
result_elements = soup.select('.b_algo')
for element in result_elements:
title_elem = element.select_one('h2 a')
snippet_elem = element.select_one('.b_caption p')
if title_elem:
url = title_elem.get('href', '')
results.append(SERPResult(
keyword=keyword,
position=position,
title=title_elem.get_text(strip=True),
url=url,
snippet=snippet_elem.get_text(strip=True) if snippet_elem else "",
domain=urlparse(url).netloc if url else ""
))
position += 1
if position > 20:
break
return results
# Data storage functions
def store_keyword_data(keyword_data: List[KeywordData]):
"""Store keyword intelligence in database."""
for kd in keyword_data:
data = {
"keyword": kd.keyword,
"frequency": kd.frequency,
"context": kd.context,
"url": kd.url,
"domain": kd.domain,
"crawled_at": time.time()
}
# Store in your preferred database (PostgreSQL, MongoDB, etc.)
redis_client.lpush(f"keyword_data:{kd.keyword}", json.dumps(data))
print(f"Stored: {kd.keyword} found {kd.frequency} times on {kd.domain}")
def store_serp_data(serp_data: List[SERPResult]):
"""Store SERP tracking data."""
for result in serp_data:
data = {
"keyword": result.keyword,
"position": result.position,
"title": result.title,
"url": result.url,
"snippet": result.snippet,
"domain": result.domain,
"tracked_at": time.time()
}
redis_client.lpush(f"serp_data:{result.keyword}", json.dumps(data))
print(f"SERP: '{result.keyword}' -> #{result.position} {result.domain}")
# Orchestration functions
def start_content_intelligence_crawl(urls: List[str], keywords: List[str]):
"""Launch content crawling across 1M+ URLs."""
print(f"Starting content intelligence crawl for {len(urls)} URLs...")
for url in urls:
crawl_content_for_keywords.delay(url, keywords)
print(f"Queued {len(urls)} content crawling tasks")
def start_serp_tracking(keywords: List[str], search_engines: List[str] = ["google", "bing"]):
"""Launch SERP tracking for target keywords."""
print(f"Starting SERP tracking for {len(keywords)} keywords...")
for keyword in keywords:
for engine in search_engines:
track_serp_rankings.delay(keyword, engine)
print(f"Queued {len(keywords) * len(search_engines)} SERP tracking tasks")
# Example usage
if __name__ == "__main__":
# Target keywords for analysis
target_keywords = [
"artificial intelligence", "machine learning", "data science",
"cloud computing", "cybersecurity", "digital transformation"
]
# URLs to crawl for content intelligence (load from your database)
content_urls = [
"<https://techcrunch.com/ai>",
"<https://venturebeat.com/ai>",
"<https://competitor-blog.com/insights>",
# ... 999,997 more URLs
]
# Keywords to track in SERPs
serp_keywords = [
"best AI tools 2026", "enterprise machine learning",
"data analytics platform", "cloud security solutions"
]
# Launch both crawling streams
start_content_intelligence_crawl(content_urls, target_keywords)
start_serp_tracking(serp_keywords)
Key Production Considerations:
- Intelligent deduplication: The system uses Redis with 24-hour expiry to avoid re-crawling the same content daily. For deeper deduplication, consider content hashing to detect pages that changed URLs but kept the same content.
- Domain-aware rate limiting: SERP crawling needs extra caution as search engines are more aggressive about blocking. Our example includes longer delays (5-10 seconds) for search queries vs content crawling (3-7 seconds).
- SERP feature tracking: The parser handles both Google and Bing results, but you can extend it to track featured snippets, local packs, and other SERP features that impact your visibility strategy.
- Data pipeline integration: Store results in your preferred database (PostgreSQL for relational analysis, MongoDB for flexible schemas).
Best Practices
Respect robots.txt or face the consequences
Parse robots.txt before queuing URLs and honor crawl-delay directives religiously. Ignoring these gets your entire IP range blacklisted faster than you can say “distributed crawler.” Build robots.txt checking directly into your URL frontier, and don’t make it the worker node’s responsibility.
Beyond robots.txt compliance, you should also implement comprehensive detection avoidance strategies across your entire distributed fleet.
Always log for 3 AM debugging
When your crawl dies at midnight, you need metadata: URL, HTTP status, latency, proxy ID, worker ID, and timestamp for every single request. JSON-structured logs save your sanity. The question isn’t whether you’ll need to debug a production failure, it’s when.
Validate everything, trust nothing
Schema validation on extracted data is needed for the survival of your distributed web crawlers, because just one malformed response can poison your entire dataset. Check field types, required fields, and data freshness at ingestion. Catch garbage early or find it corrupting your analysis months later.
Fight speed debt ruthlessly
Distributed systems rot fast. You need to schedule monthly cleanup of stale Redis keys, failed task queues, and orphaned worker processes. Dead URLs pile up, proxy pools get polluted with blocked IPs, and worker memory leaks compound over time. Maintenance isn’t glamorous, but it keeps your crawler healthy. Technical debt in crawlers compounds exponentially, so address it before it breaks your system.
Common Pitfalls of Distributed Crawling and How to Avoid Them
There are numerous common pitfalls that people face when using distributed web crawling, which is why most engineers seek alternatives, such as Bright Data’s datasets. Some of these pitfalls include:
The “Single Point of Failure” Trap
Building everything around one Redis instance or master coordinator is a bad idea. When it dies, your entire crawl stops dead.
Fix: Use Redis Cluster or multiple broker instances. Design for the coordinator to disappear, so workers should gracefully handle broker outages and reconnect automatically.
The Retry Death Spiral
When failed URLs immediately go back into the main queue, it creates an infinite loop that hammers broken endpoints and clogs your pipeline.
Fix: Separate retry queues with exponential backoff. First retry after 1 minute, then 5, then 30. After 3 failures, send to a dead letter queue for manual review.
The All Workers Are Equal Fallacy
Round-robin task distribution assumes every worker has the same network speed, proxy quality, and processing power. Reality is often messier.
Fix: Implement worker scoring based on success rate, latency, and throughput. Route harder jobs to your best performers.
The Memory Leak Time Bomb
Workers that never restart accumulate memory leaks, especially when parsing malformed HTML or handling large responses. If left alone, your distributed web crawling performance degrades until workers crash.
Fix: Restart workers after processing 1000 tasks or every 4 hours. Monitor memory usage and implement circuit breakers.
Conclusion
You now have the blueprint for distributed crawling that scales to millions of pages. To deepen your understanding of web crawling fundamentals that underpin distributed systems, read our comprehensive web crawler overview.
The architecture is straightforward, but the brutal truth is 90% of teams still fail because they underestimate the anti-detection complexity of a distributed web crawling system. Managing thousands of proxies, rotating fingerprints, and handling CAPTCHAs becomes a full-time engineering nightmare that distracts from extracting valuable data.
This is exactly why Bright Data’s Web Unlocker API exists. Instead of burning months building proxy infrastructure that breaks every week, your distributed workers simply route requests through Web Unlocker’s 99%+ success rate API.
No proxy management, no fingerprint rotation, no CAPTCHA solving—just reliable data extraction at scale. Your engineering team focuses on building business logic while Bright Data handles the cat-and-mouse games with anti-bot systems.
The math is simple: homegrown anti-detection costs months of engineering time plus ongoing maintenance headaches, while Web Unlocker costs a fraction of that while delivering enterprise-grade reliability. So stop reinventing the wheel and start extracting insights. Get your free Bright Data account today and turn your distributed crawler from a maintenance burden into a competitive advantage.

Technical Writer
Arindam Majumder is a developer advocate, YouTuber, and technical writer who simplifies LLMs, agent workflows, and AI content for 5,000+ followers.




