

In this guide, you will learn:
- What zero-shot classification is and how it works
- Pros and cons of using it
- Relevance of this practice in web scraping
- Step-by-step tutorial to implement zero-shot classification in a web scraping scenario
Let’s dive in!
What Is Zero-Shot Classification?
Zero-shot classification (ZSC) is the ability of predicting a class that a machine learning model has never seen during its training phase. A class is a specific category or label that the model assigns to a piece of data. For example, it could assign the class “spam” to the text of an email, or “cat” to an image.
ZSC can be classified as an instance of transfer learning. Transfer learning is a machine learning technique where you apply the knowledge gained from solving one problem to help solve a different, but related problem.
The core idea of ZSC has been explored and implemented in several types of neural networks and machine learning models for a while. It can be applied to different modalities, including:
- Text: Imagine you have a model trained to understand language broadly, but you have never shown it an example of a “product review for sustainable packaging.” With ZSC, you can ask it to identify such reviews from a pile of text. It does this by understanding the meaning of your desired categories (labels) and matching them to the input text, rather than relying on pre-learned examples for each specific label.
- Images: A model trained on a set of animal images (e.g., cats, dogs, horses) might be able to classify an image of a zebra as an “animal” or even a “striped horse-like animal” without ever having seen a zebra during training.
- Audio: A model might be trained to recognize common urban sounds like “car horn,” “siren,” and “dog bark.” Thanks to ZSC, a model can identify a sound it has never been explicitly trained on, such as “jackhammer,” by understanding its acoustic properties and relating them to known sounds.
- Multimodal data: ZSC can work across different types of data, such as classifying an image based on a textual description of a class it has never seen, or vice versa.
How Does ZSC Work?
Zero-shot classification is gaining interest thanks to the popularity of pre-trained LLMs. These models are trained on massive amounts of AI-oriented data, allowing them to develop a deep understanding of language, semantics, and context.
For ZSC, pre-trained models are often fine-tuned on a task called NLI (Natural Language Inference). NLI involves determining the relationship between two pieces of text: a “premise” and a “hypothesis.” The model decides if the hypothesis is an entailment (true given the premise), a contradiction (false given the premise), or neutral (unrelated).
In a zero-shot classification setup, the input text acts as the premise. The candidate category labels are treated as hypotheses. The model calculates which “hypothesis” (label) is most likely entailed by the “premise” (input text). The label with the highest entailment score is chosen as the classification.
Advantages and Limitations of Using Zero-Shot Classification
Time to explore the benefits and drawbacks of ZSC.
Advantages
ZSC presents several operational benefits, including:
- Adaptability to novel classes: ZSC opens the door to the classification of data into unseen categories. It does that by defining new labels without requiring model retraining or the collection of specific training examples for the new classes.
- Reduced labeled data requirement: The method lessens the dependency on extensive labeled datasets for the target classes. This mitigates data labeling—a common bottleneck in machine learning project timelines and costs.
- Efficient classifier implementation: New classification schemes can be configured and evaluated quickly. That facilitates faster iteration cycles in response to evolving requirements.
Limitations
While powerful, zero-shot classification comes with limitations such as:
- Performance variability: ZSC-powered models may exhibit lower accuracy compared to supervised models trained extensively on fixed class sets. That happens because ZSC relies on semantic inference rather than direct training on target class examples.
- Dependence on model quality: The performance of ZSC relies on the quality and capabilities of the underlying pre-trained language model. A powerful base model generally leads to better ZSC results.
- Label ambiguity and phrasing: Clarity and distinctiveness of the candidate labels influence accuracy. Ambiguous or poorly defined labels can result in suboptimal performance.
The Relevance of Zero-Shot Classification in Web Scraping
The continuous emergence of new information, products, and topics on the Web demands adaptable data processing methods. It all starts with web scraping—the automated process of retrieving data from web pages.
Traditional machine learning methods require manual categorization or frequent retraining to handle new classes in scraped data, which is inefficient at scale. Instead, zero-shot classification addresses the challenges posed by the dynamic nature of web content by enabling:
- Dynamic categorization of heterogeneous data: Scraped data from diverse sources can be classified in real-time using a user-defined set of labels pertinent to current analytical objectives.
- Adaptation to evolving information landscapes: New categories or topics can be incorporated into the classification schema immediately, without the need for extensive model redevelopment cycles.
Thus, typical ZSC use cases in web scraping are:
- Dynamic content categorization: When scraping content such as news articles or product listings from multiple domains, ZSC can automatically assign items to predefined or new categories.
- Sentiment analysis for novel subjects: For scraped customer reviews of new products or social media data related to emergent brands, ZSC can perform sentiment analysis without requiring sentiment training data specific to that product or brand. This facilitates timely brand perception monitoring and customer feedback assessment.
- Identification of emerging trends and themes: By defining hypothesis labels representing potential new trends, ZSC can be used to analyze scraped text from forums, blogs, or social media to identify the increasing prevalence of these themes.
Practical Implementation of Zero-Shot Classification
This tutorial section will guide you through the process of applying zero-shot classification to data retrieved from the Web. The target site will be “Hockey Teams: Forms, Searching and Pagination”:

First, a web scraper will extract the data from the above table. Then, an LLM will classify it using ZSC. For this tutorial, you will use the DistilBart-MNLI from Hugging Face: a lightweight LLM of the BART family.
Follow the steps below and see how to achieve the desired ZSC goal!
Prerequisites and Dependencies
To replicate this tutorial, you must have Python 3.10.1 or higher installed on your machine.
Suppose you call the main folder of your project zsc_project/. At the end of this step, the folder will have the following structure:
zsc_project/
├── zsc_scraper.py
└── venv/Where:
zsc_scraper.pyis the Python file that contains the coding logic.venv/contains the virtual environment.
You can create the venv/ virtual environment directory like so:
python -m venv venvTo activate it, on Windows, run:
venvScriptsactivateEquivalently, on macOS and Linux, execute:
source venv/bin/activateIn the activated virtual environment, install the dependencies with:
pip install requests beautifulsoup4 transformers torchThese dependencies are:
requests: A library for making HTTP web requests.beautifulssoup4: A library for parsing HTML and XML documents and extract data from them. Learn more in our guide on BeautifulSoup web scraping.transformers: A library by Hugging Face that provides thousands of pretrained models.torch: PyTorch, an open-source machine learning framework.
Wonderful! You now have what you need to extract the data from the target website and to perform ZSC.
Step #1: Initial Setup and Configuration
Initialize the zsc_scraper.py file by importing the required libraries and setting up some variables:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process The above code does the following:
- Defines the target website to scrape with
BASE_URL. CANDIDATES_LABELSstores a list of strings that define the categories that the zero-shot classification model will use to classify the scraped data. The model will try to determine which of these labels best describes each piece of team data.- Defines the maximum number of pages to scrape and the maximum number of teams’ data to retrieve.
Perfect! You have what it takes to get started with zero-shot classification in Python.
Step #2: Fetch the Page URLs
Start by inspecting the pagination element on the target page:

Here, you can notice that the pagination URLs are contained in a .pagination HTML node.
Define a function for finding all the unique page URLs from the pagination section of the website:
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urlsThis function:
- Sends an HTTP request to the target website with the method
get(). - Manages pagination with the method
select()from BeautifulSoup. - Iterates through each page, ensuring a consistent order, with a
forloop. - Returns the list of all unique, full-page URLs.
Cool! You have created a function to fetch the URLs of the web pages to scrape data from.
Step #3: Scrape The Data
Start by inspecting the pagination element on the target page:

Here, you can see that the teams’ data to scrape is contained in a .table HTML node.
Create a function that takes a single-page URL, fetches its content, and extracts team statistics:
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_dataThis function:
- Retrieves the data from the table rows with the method
select(). - Processes each team row with the
for row in table_rows:loop. - Returns the fetched data in a list.
Well done! You have created a function to retrieve the data from the target website.
Step #4: Orchestrate The Process
Coordinate the entire workflow in the following steps:
- Load the classification model
- Fetch the URLs of the pages to scrape
- Scrape data from each page
- Classify the scraped text with ZSC
Achieve that with the following code:
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")This code:
- Loads the pretrained model with the method
pipeline()and specifies its task with"zero-shot-classification". - Calls the previous functions and performs the actual ZSC.
Perfect! You created a function that orchestrates all the previous steps and performs the actual zero-shot classification.
Step #5: Put It All Together And Run The Code
Below is what the zsc_scraper.py file should now contain:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process per page
# Fetch page URLs
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urls
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_data
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")Very well! You have completed your first ZSC project.
Run the code with the following command:
python zsc_scraper.pyThis is the expected result:
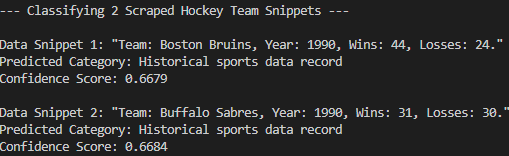
As you can see, the model has correctly classified the scraped data into the “Historical sports data record.” That would not have been possible without zero-shot classification. Mission complete!
Conclusion
In this article, you learned what zero-shot classification is and how to apply it in a web scraping context. Web data is constantly changing, and you can not expect a pre-trained LLM to know everything in advance. ZSC helps bridge that gap by dynamically classifying new information without retraining.
However, the real challenge lies in obtaining fresh data—since not all websites are easy to scrape. That is where Bright Data comes in, offering a suite of powerful tools and services designed to overcome scraping obstacles. These include.
- Web Unlocker: An API that bypasses anti-scraping protections and delivers clean HTML from any webpage with minimal effort.
- Scraping Browser: A cloud-based, controllable browser with JavaScript rendering. It automatically handles CAPTCHAs, browser fingerprinting, retries, and more for you. It integrates seamlessly with Panther or Selenium PHP.
- Web Scraper APIs: Endpoints for programmatic access to structured web data from dozens of popular domains.
For the machine learning scenario, also explore our AI hub.
Sign up for Bright Data now and start your free trial to test our scraping solutions!

Technical Writer
Federico Trotta is a technical writer, editor, and data scientist. Expert in technical content management, data analysis, machine learning, and Python development.




