









Discover the art of fast data gathering from various websites by mastering web scraping with Python. Save time and effort with these essential skills!
Watch our web scraping with Python tutorial
Web scraping is about extracting data from the Web. Specifically, a web scraper is a tool that can perform web scraping. Python is one of the easiest scripting languages available and comes with a wide variety of web scraping libraries. This makes it the perfect programming language for web scraping. Python web scraping takes only a few lines of code!
In this step-by-step tutorial, you will learn how to build a simple Python scraper. This application will go through an entire website, extract data from each page, and export it to a CSV file. This tutorial will help you understand which are the best Python data scraping libraries, which ones to adopt, and how to use them. Follow this step-by-step tutorial and learn how to build a web scraping Python script.
Table of content:
Prerequisites
To build a Python web scraper, you need the following prerequisites:
- Python 3.4+
- pip
Note that pip is included by default in Python version 3.4 or later. So, it is not required to install it manually. If you do not have Python on your computer, follow the guide below for your operating system.
macOS
Macs used to come with Python 2.7 preinstalled, but this is no longer the case. Actually, that version is now deprecated.
If you want the latest version of Python, you must install it manually. To do so, download the installer, double-click on it to launch it, and follow the setup wizard.
Windows
Download the Python installer and run it. During the installation wizard, make sure to mark the “Add python.exe to PATH” checkbox as below:
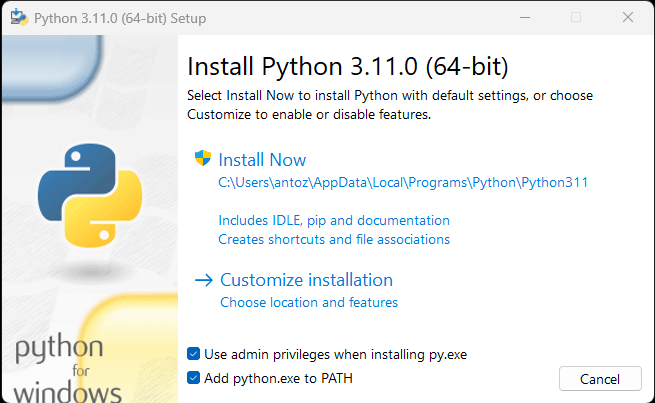
This way, Windows will automatically recognize the python and pip commands in the terminal. In detail, pip is a package manager for Python packages.
Linux
Most Linux distributions have Python preinstalled, but it may not be the latest version. The command to install or update Python on Linux changes depending on the package manager. In Debian-based Linux distributions, run:
sudo apt-get install python3Regardless of your OS, open the terminal and verify that Python has been installed successfully with:
python --versionThis should print something like:
Python 3.11.0You are now ready to build your first Python web scraper. But first, you need a Python web scraping library!
Best Python Web Scraping Libraries
You can build a web scraping script from scratch with Python vanilla, but that is not the ideal solution. After all, Python is well known for its wide selection of packages and there are many web scraping libraries to choose from. Time to have a look at the most important ones!
Requests
The requests library allows you to perform HTTP requests in Python. It makes sending HTTP requests easy, especially compared to the standard Python HTTP library. requests plays a key role in a Python web scraping project. The reason is that to scrape the data contained in a web page, you first have to retrieve it via an HTTP GET request. Also, you may have to perform other HTTP requests to the server of the target website.
You can install requests with the following pip command:
pip install requestsBeautiful Soup
The Beautiful Soup Python library makes scraping information from web pages easier. In particular, Beautiful Soup works with any HTML or XML parser and provides everything you need to iterate, search, and modify the parse tree. Note that you can use Beautiful Soup with html.parser, the parser that comes with the Python Standard Library and allows you to parse HTML text files. In particular, Beautiful Soup helps you traverse the DOM and extract the data you need from it.
You can install Beautiful Soup with the pip as follows:
pip install beautifulsoup4Selenium
Selenium is an open-source, advanced, automated testing framework that enables you to execute operations on a web page in a browser. In other terms, you can harness it to instruct a browser to perform certain tasks. Note that you can also use Selenium as a web scraping library for its headless browser capabilities. If you are not familiar with this concept, a headless browser is a web browser that runs without a GUI (Graphical User Interface). If configured in headless mode, Selenium will run the controlled browser behind the scene.
The web pages visited in Selenium are rendered in a real browser. As a result, it supports scraping web pages that depend on JavaScript for rendering or data retrieval. Selenium equips you with everything you need to build a web scraper, without the need for other libraries. You can install it with the following pip command:
pip install seleniumBuilding a Web Scraper in Python
Let’s now learn how to build a web scraper in Python. This is what the target site looks like:
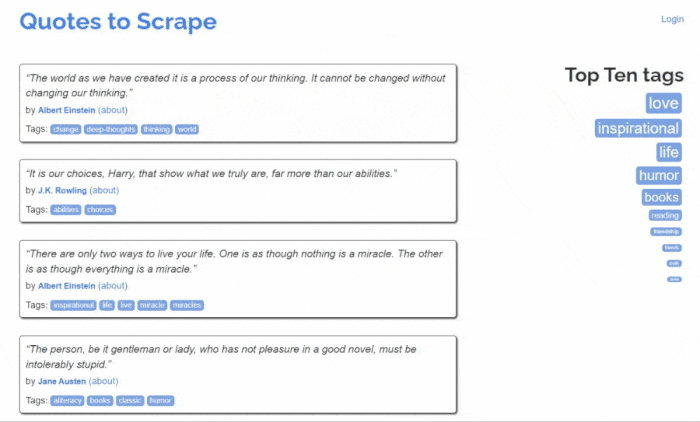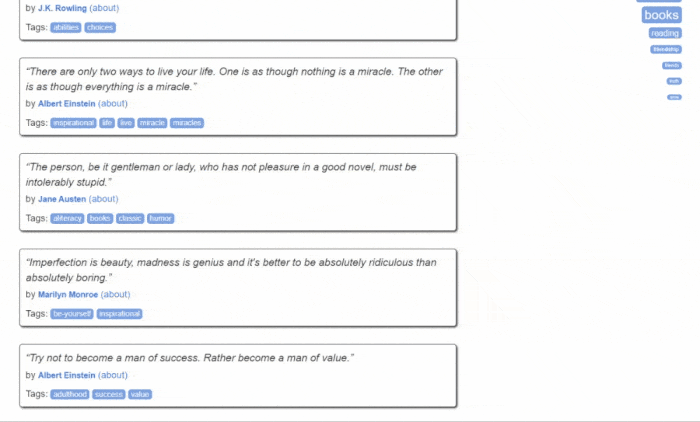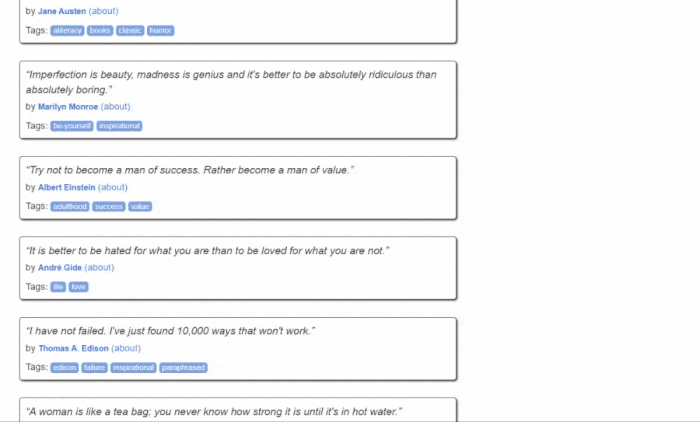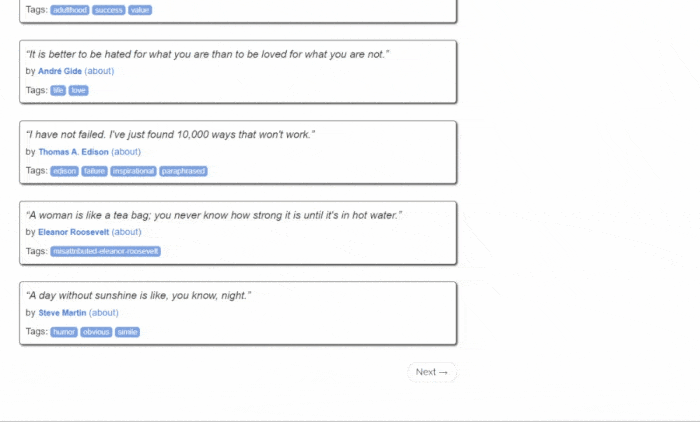
That is the Quotes to Scrape site, a sandbox for web scraping that contains a paginated list of quotes.
The goal of this tutorial is to learn how to extract all quote data from it. For each quote, you will learn how to scrape the text, author, and list of tags. Then the scraped data will be converted to CSV.
As you can see, Quotes to Scrape is nothing more than a sandbox for web scraping. Specifically, it contains a paginated list of quotes. The Python web scraper you are going to build will retrieve all the citations contained on each page and return them as CSV data.
Step 1: Choose the right Python scraping libraries
First of all, you need to understand what are the best web scraping libraries in Python to achieve the goal. To do this, visit the target site in your site browser. Right-click on the background and select “Inspect.” The DevTools browser window will open. Reach the Network tab and reload the page.
As you will note, the target website does not perform any Fetch/XHR request.
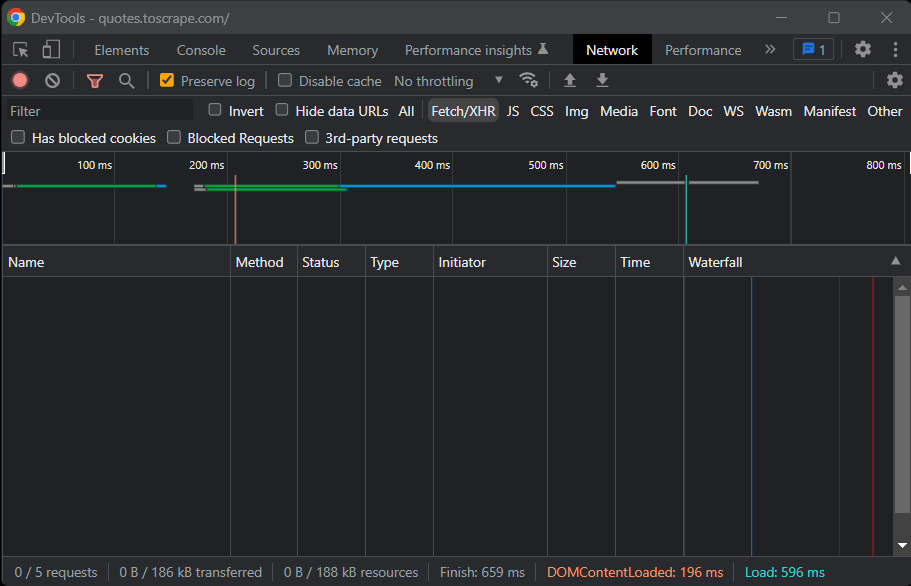
This means Quotes to Scrape does not rely on JavaScript to dynamically retrieve data. In other terms, the pages returned by the server already contain the data of interest. This is what happens in static-content sites.
Since the target website does not rely on JavaScript to render the page or retrieve data, you do not need Selenium to scrape it. You can still use it, but you should not. The reason is Selenium opens web pages in a browser. Since this takes time and resources, Selenium introduces a performance overhead. You can avoid that by using Beautiful Soup together with Requests.
Now that you understood what Python scraping libraries to use, learn how to build a simple scraper with Beautiful Soup!
Step 2: Initialize a Python project
Before writing the first line of code, you need to set up your Python web scraping project. Technically, you only need a single .py file. However, using an advanced IDE (Integrated Development Environment) will make your coding experience easier. Here, you are going to learn how to set up a Python project in PyCharm, but any other Python IDE will do.
Open PyCharm and select “File > New Project…”. In the “New Project” popup window, select “Pure Python” and create a new project.
For example, you can call your project python-web-scraper. Click “Create” and you will now have access to your blank Python project. By default, PyCharm will initialize a main.py file. For the sake of clarity, rename it to scraper.py. This is what your project will now look like:
As you can see, PyCharm automatically initializes the Python file with some lines of code. Delete them to start from scratch.
Next, you have to install the project’s dependencies. You can install Requests and Beautiful Soup by launching the following command in the terminal:
pip install requests beautifulsoup4This will install the two libraries at once. Wait for the installation process to complete. You are now ready to you use Beautiful Soup and Requests to build your web crawler and scraper in Python. Make sure of importing the two libraries by adding the following lines to the top of your scraper.py script file:
import requests
from bs4 import BeautifulSoupPyCharm will show these two lines in gray because the libraries are not used in the code. If it underlines them in red, it means that something went wrong during the installation process. In this case, try to install them again.
Great! You are now ready to start writing some Python web scraping logic.
Step 3: Connect to the target URL
The first thing to do in a web scraper is to connect to your target website. First, retrieve the complete URL of the target page from your web browser. Make sure to copy also the http:// or https:// HTTP protocol section. In this case, this is the entire URL of the target website:
https://quotes.toscrape.comNow, you can use requests to download a web page with the following line of code:
page = requests.get('https://quotes.toscrape.com')This line simply assigns the result of the request.get() method to the variable page. Behind the scene, request.get() performs a GET request using the URL passed as a parameter. Then, it returns a Response object containing the server response to the HTTP request.
If the HTTP request is executed successfully, page.status_code will contain 200. The HTTP 200 OK status response code indicates that the HTTP request was executed successfully. A 4xx or 5xx HTTP status code will represent an error. This may happen for several reasons, but keep in mind that most websites block requests that do not contain a valid User-Agent. That special header is a string that characterizes the application and operating system version from where a request comes from. Learn more about User-Agents for web scraping.
You can set a valid User-Agent header in requests as follows:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get('https://quotes.toscrape.com', headers=headersrequests will now execute the HTTP request will the headers passed as a parameter.
What you should pay attention to is the page.text property. This will contain the HTML document returned by the server in string format. Feed the text property to Beautiful Soup to extract data from the web page. Let’s learn how.
What you should pay attention to is the page.text property. That will contain the HTML document returned by the server in string format. Feed the text property to Beautiful Soup to parse the web page. Let’s learn how in the next step!
Step 4: Parse the HTML content
To parse the HTML document returned by the server after the GET request, pass page.text to the BeautifulSoup() constructor:
soup = BeautifulSoup(page.text, 'html.parser')The second parameter specifies the parser that Beautiful Soup will use.
The soup variable now contains a BeautifulSoup object. That is a tree structure generated from parsing the HTML document contained in page.text with the Python built-in html.parser.
You can now use it to select the desired HTML element from the page. See how!
Step 5: Select HTML elements with Beautiful Soup
Beautiful Soup offers several approaches for selecting elements from the DOM. The starting points are:
- find(): Returns the first HTML element that matches the input selector stragety, if any.
- find_all(): Returns a list of HTML elements matching the selector condition passed as a parameter.
Based on the parameters fed to these two methods, they will look for elements on the page in different ways. Specifically, you can select HTML elements:
- By tag:
# get all <h1> elements
# on the page
h1_elements = soup.find_all('h1')
- By id:
# get the element with id="main-title"
main_title_element = soup.find(id='main-title')- By text:
# find the footer element
# based on the text it contains
footer_element = soup.find(text={'Powered by WordPress'})- By attribute:
# find the email input element
# through its "name" attribute
email_element = soup.find(attrs={'name': 'email'})- By class:
# find all the centered elements
# on the page
centered_element = soup.find_all(class_='text-center')
By concatenating these methods, you can extract any HTML element from the page. Take a look at the example below:
# get all "li" elements
# in the ".navbar" element
soup.find(class_='navbar').find_all('li')To make things easier, Beautiful Soup also has the select() method. This enables you to apply a CSS selector directly:
# get all "li" elements
# in the ".navbar" element
soup.select('.navbar > li')Note that XPath selectors are note supported at the time of writing.
What is important to learn is that to extract data from a web page, you must first identify the HTML elements of interest. In particular, you must define a selection strategy for the elements that contain the data you want to scrape.
You can achieve that by using the development tools offered by your browser. In Chrome, right-click on the HTML element of interest and select the “Inspect” option. In this case, do that on a quote element.
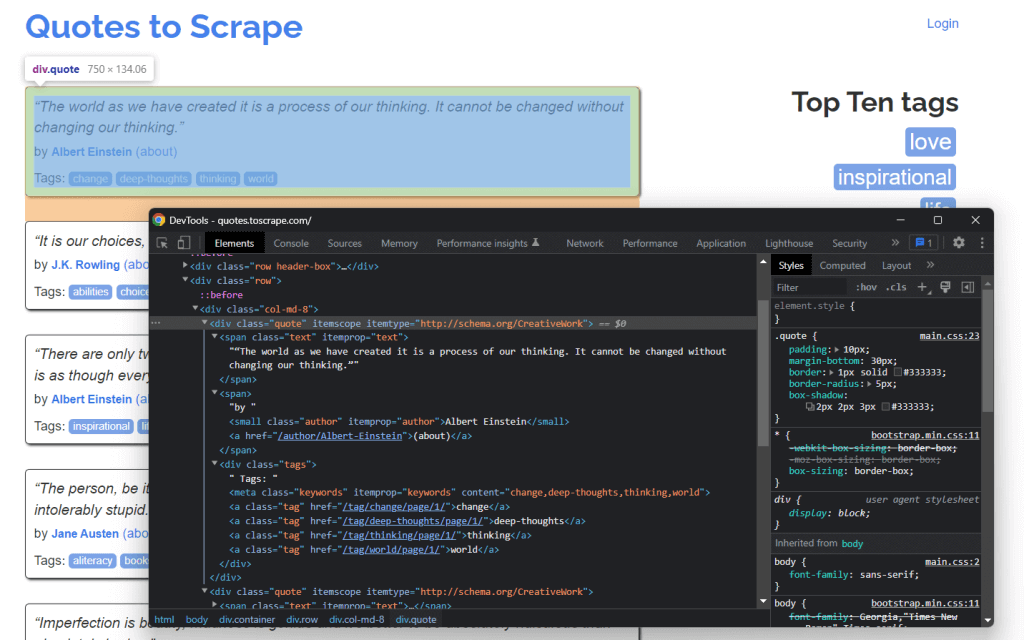
As you can see here, the quote <div> HTML element is identified by quote class. This contains:
- The quote text in a
<span>HTML element - The author of the quote in a
<small>HTML element - A list of tags in a
<div>element, each contained in<a>HTML element
In detail, you can extract this data using the following CSS selectors on .quote:
.text.author.tags .tag
Step 6: Extract data from the elements
First, you need a data structure where to store the scraped data. For this reason, initialize an array variable.
quotes = []Then, use soup to extract the quote elements from the DOM by applying the .quote CSS selector defined earlier:
quote_elements = soup.find_all('div', class_='quote')The find_all() method will return the list of all <div> HTML elements identified by the quote class. Iterate over the quotes list to retrieve the quote data as below:
for quote_element in quote_elements:
# extract the text of the quote
text = quote_element.find('span', class_='text').text
# extract the author of the quote
author = quote_element.find('small', class_='author').text
# extract the tag <a> HTML elements related to the quote
tag_elements = quote_element.select('.tags .tag')
# store the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)The Beautiful Soup find() method will retrieve the single HTML element of interest. Since the tag strings associated with the quote are more than one, you should store them in a list.
Then, you can transform the scraped data into a dictionary and append it to the quotes list as follows:
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merge the tags into a "A, B, ..., Z" string
}
)Storing the data in structured dictionary makes to access and understand it.
Great! You just saw how to extract all quote data from a single page! Yet, keep in mind that the target webiste consists of several web pages. It is time to learn how to crawl the entire website!
Step 7: Implement the crawling logic
At the bottom of the home page, you can find a “Next →” <a> HTML element that redirects to the next page. This HTML element is contained on all but the last page. Such a scenario is common in any paginated website.
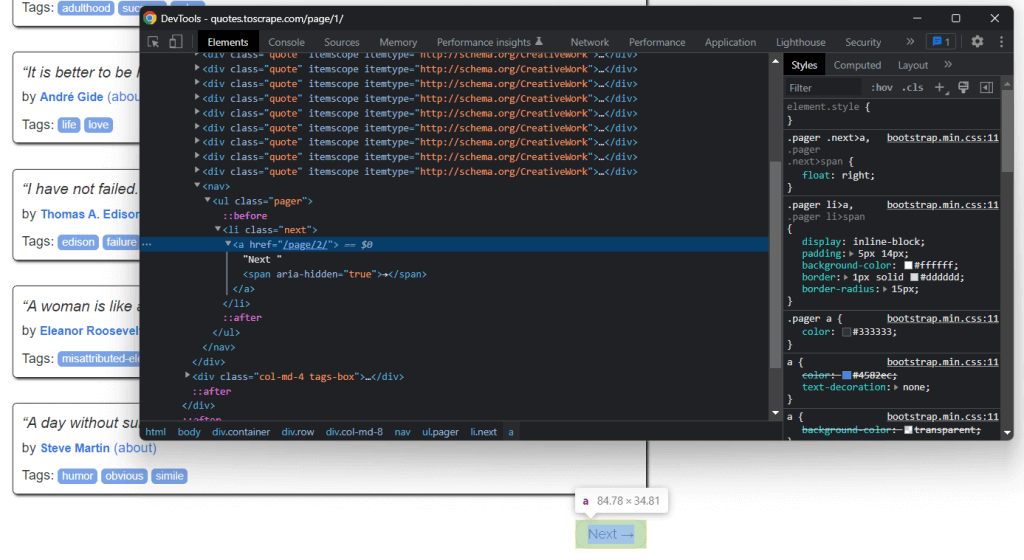
By following the link contained in that HTML element, you can easily navigate the entire website. So, start from the home page and see how to go through each page that the target website consists of. All you have to do is look for the .next <li> HTML element and extract the relative link to the next page.
You can implement the crawling logic as follows:
# the URL of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# retrieve the page and initializing soup...
# get the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# get the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parse the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# look for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')The where cycle iterates over each page until there is no next page. In particular, it extracts the relative URL of the next page and uses it to create the URL of the next page to scrape. Then, it downloads the next page. Next, it scrapes it and repeats the logic.
Fantastic! You now know how to scrape an entire website. It only remains to learn how to convert the extracted data to a more useful format, such as CSV.
Step 8: Extract the scraped data to a CSV file
Let’s see how to export the list of dictionaries containing the scraped quote data to a CSV file. Achieve this with the following lines:
import csv
# scraping logic...
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()What this snippet does is write the quote data contained in the list of dictionaries in a quotes.csv file. Note that csv is part of the Python Standard Library. So, you can import and use it without installing an additional dependency.
In detail, you simply have to create a CSV file with open(). Then, you can populate it with the writerow() function from the Writer object of the csv library. This will write each quote dictionary as a CSV-formatted row.
You went from raw data contained in a website to semi-structured data stored in a CSV file. The data extraction process is over and you can now take a look at the entire Python data scraper.
Step 9: Put it all together
This is what the complete data scraping Python script looks like:
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# retrieving all the quote <div> HTML element on the page
quote_elements = soup.find_all('div', class_='quote')
# iterating over the list of quote elements
# to extract the data of interest and store it
# in quotes
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
# appending a dictionary containing the quote data
# in a new format in the quote list
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# defining the User-Agent header to use in the GET request below
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# retrieving the target web page
page = requests.get(base_url, headers=headers)
# parsing the target web page with Beautiful Soup
soup = BeautifulSoup(page.text, 'html.parser')
# initializing the variable that will contain
# the list of all quote data
quotes = []
# scraping the home page
scrape_page(soup, quotes)
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping the new page
scrape_page(soup, quotes)
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()As shown here, in less than 100 lines of code you can build a web scraper. This Python script is able to crawl an entire website, automatically extract all its data, and export it to CSV.
Congrats! You just learned how to build a Python web scraper with Requests and Beautiful Soup!
Step 10: Run the Python web scraping script
If you are a PyCharm user, run the script by clicking the button below:

Otherwise, launch the following Python command in the terminal inside the project’s directory:
python scraper.pyWait for the process to end, and you will now have access to a quotes.csv file. Open it, and it should contain the following data:
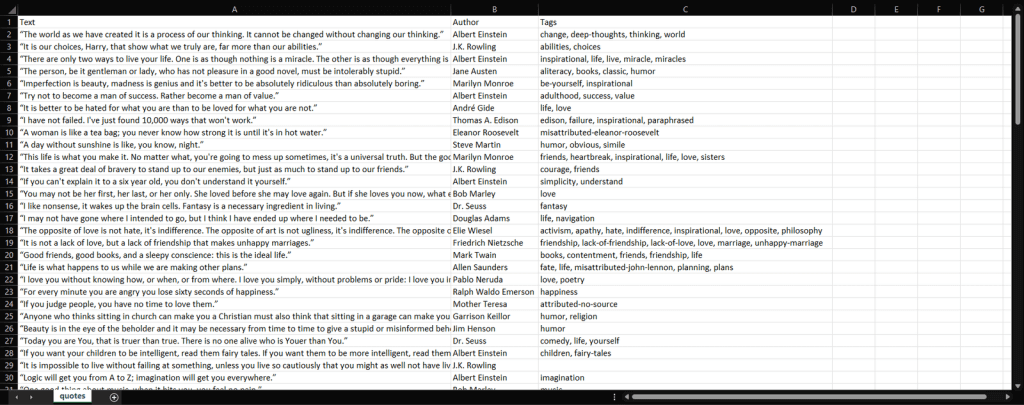
Et voilà! You now have all 100 quotes contained in the target website in a single file in an easy-to-read format!
Conclusion
In this tutorial, you learned what scraping the Web with Python is, what you need to get started in Python, and what are the best web scraping Python libraries. Then, you saw how to use Beautiful Soup and Requests to build a web scraping application through a real-world example. As you learned, web scraping in Python takes only a few lines of code.
However, web scraping comes with several challenges. In detail, anti-bot and anti-scraping technologies have become increasingly popular. And this is where proxies come in.
A proxy server acts as an intermediary between your scraping script in X and the target pages. It receives your requests, forwards them to the destination server, receives the responses, and sends them back to you. This way, the target site will see their IPs and not yours. That means hiding your IP to preserve its reputation and save your privacy, avoiding bans and geo-restrictions. Thanks to rotating proxies, you can get fresh IPs at every request to bypass even rate-limiting systems.
It only remains to select a reliable provider that can give you access to top-notch proxy servers with reputable IPs. Bright Data is the most popular proxy provider in the world, serving dozens of Fortune 500 companies and over 20,000 customers. Its worldwide proxy network involves:
- Datacenter proxies – Over 770,000 IPs from datacenters.
- Residential proxies – Over 72M IPs from residential devices in more than 195 countries.
- ISP proxies – Over 700,000 IPs from ISP-registered devices.
- Mobile proxies – Over 7M IPs from mobile networks.
FAQs
Python is not only a good choice for web scraping, it is actually considered one of the best languages for that. This is because of its readability and low learning curve. On top of that, it comes with of the largest communities in the IT world and a wide selection of libraries and tools designed for web scraping.
Yes, web scraping and crawling are part of the greater field of data science. Scraping/crawling serves as the foundation for all other by-products that can be derived from structured, and unstructured data. This includes analytics, algorithmic models/output, insights, and ‘applicable knowledge’.
Scraping data from a website using Python entails inspecting the page of your target URL, identifying the data you would like to extract, writing and running the data extraction code, and finally storing the data in your desired format.
The first step to building a Python data scraper is utilizing string methods in order to parse website data, then parsing website data using an HTML parser, and finally interacting with necessary forms and website components.




