

This tutorial will teach you how to build a Kotlin web scraping script. Specifically, you will learn:
- Why Kotlin is a great language for scraping a site
- What the best Kotlin scraping libraries are.
- How to build a Kotlin scraper from scratch.
Let’s dive in!
Is Kotlin a Viable Option for Web Scraping?
TL;DR: Yes, it is! And may also be even better than Java!
Kotlin is a statically typed, cross-platform, general-purpose programming language whose standard library depends on the Java Class Library. What makes Kotlin special is its concise and fun approach to coding. It is endorsed by Google, which has chosen it as its preferred language for Android development.
Thanks to its interoperability with the JVM, it supports all Java scraping libraries. Thus, you can take advantage of the vast ecosystem of Java libraries, but with a more concise and intuitive syntax. That is a win-win scenario!
In addition, Kotlin comes with some native libraries, which include HTML parsers and browser automation libraries, that simplify data extraction. Explore some of the most popular ones!
Best Kotlin Web Scraping Libraries
Here is a list of some of the best web scraping libraries for Kotlin:
- skrape{it}: A Kotlin-based HTML/XML testing and web scraping library for parsing and interpreting HTML. It includes several data fetchers that allow skrape{it} to act both as a traditional HTML parser and as a headless browser for client-side DOM rendering.
- chrome-reactive-kotlin: A low-level DevTools Protocol client written in Kotlin for controlling Chromium-based browser programmatically.
- ksoup: A lightweight Kotlin library inspired by Jsoup. Ksoup provides methods to parse HTML, extract HTML tags, attributes, and text, and encode and decode HTML entities.
Don’t forget that Kotlin is interoperable with Java. This means that you can use any other web scraping library in Java. One of these is Jsoup, one of the most popular HTML parsers available. Learn more in our guide on web scraping with Jsoup.
Prerequisites
Follow the instructions below to set up your web scraping Kotlin environment.
Set Up the Environment
To write and run a Kotlin application on your machine, you need a JDK (Java Development Kit) installed locally. Download the latest LTS version of the JDK from the Oracle site, execute the installer, and follow the installation wizard. As of this writing, it is Java 21.
Then, you will need a tool to manage dependencies and build your Kotlin application. Both Gradle and Maven are great options, so you are free to choose your favorite Java build tool. Since Gradle supports Kotlin as a DSL (Domain-Specific Language) language, we will go for Gradle. Keep in mind that you can easily follow the tutorial even if you are a Maven user.
Download Maven or Gradle and install it. Gradle is particularly sensitive to the version of Java, so be sure to download the right package. The working Gradle for Java 21 is greater than or equal to version 8.5.
Finally, you will need a Kotlin IDE. Visual Studio Code with the Kotlin Language extension and IntelliJ IDEA Community Edition are both two great free choices.
Done! You now have a Kotlin-ready environment in place!
Create a Kotlin Project
Create a project folder for your Kotlin web scraping project and enter it in the terminal:
mkdir KotlinWebScraper
cd KotlinWebScraperHere we called the directory KotlinWebScraper, but feel free to give it whatever name you want
Next, launch the command below in the project folder to create a Gradle application:
gradle init --type kotlin-applicationDuring the procedure, you will be asked a few questions. You should choose “Kotlin” as the build script DSL and give your application a proper package name like com.kotlin.scraper. For the other questions, the default answers should be fine.
This is what you will see at the end of the initialization process:
Select build script DSL:
1: Kotlin
2: Groovy
Enter selection (default: Kotlin) [1..2] 1
Project name (default: KotlinWebScraper):
Source package (default: kotlinwebscraper): com.kotlin.scraper
Enter target version of Java (min. 8) (default: 21):
Generate build using new APIs and behavior (some features may change in the next minor release)? (default: no) [yes, no]
> Task :init
To learn more about Gradle by exploring our Samples at https://docs.gradle.org/8.5/samples/sample_building_kotlin_applications.html
BUILD SUCCESSFUL in 2m 10s
2 actionable tasks: 2 executedFantastic! The KotlinWebScraper folder will now contain a Gradle project.
Open the folder in your Kotlin IDE, wait for the required background tasks to be completed, and take a look at the main App.kt file inside the com.kotlin.scraper package. This is what it should contain:
/*
* This Kotlin source file was generated by the Gradle 'init' task.
*/
package com.kotlin.scraping.demo
class App {
val greeting: String
get() {
return "Hello World!"
}
}
fun main() {
println(App().greeting)
}This is a simple Kotlin script that prints “Hello World!” in the terminal.
To verify that it works, launch the script with the following Gradle command:
./gradlew runWait for the project to be built and run, and you will see:
> Task :app:run
Hello World!
BUILD SUCCESSFUL in 3s
3 actionable tasks: 2 executed, 1 up-to-dateYou can ignore the Gradle log messages. Focus instead on the “Hello World!” message, which is exactly the output you expected from the script. In other words, your Kotlin setup works as intended.
It is time to perform web scraping with Kotlin!
Build a Web Scraping Kotlin Script
In this step-by-step section, you will see how to build a web scraper in Kotlin. In particular, you will learn how to define an automated script that extracts data from the Quotes scraping sandbox site.
At a high level, the Kotlin web scraping script you are about to code will:
- Connect to the target page.
- Select the quote HTML elements on the page.
- Extract the desired data from them.
- Repeat this operation for all quotes on the sites, visiting each pagination page.
- Export the collected data in CSV format.
Here is what the target site looks like:
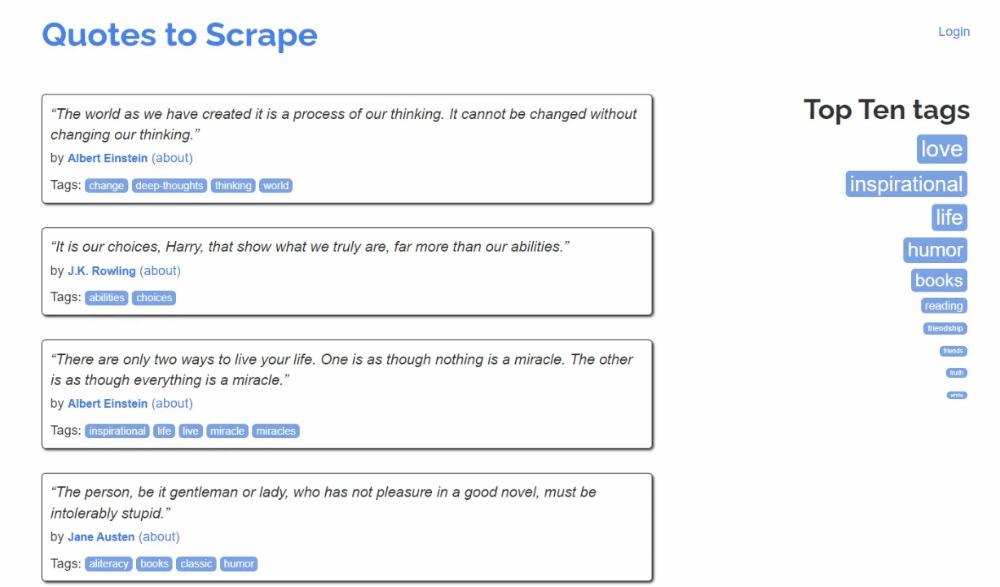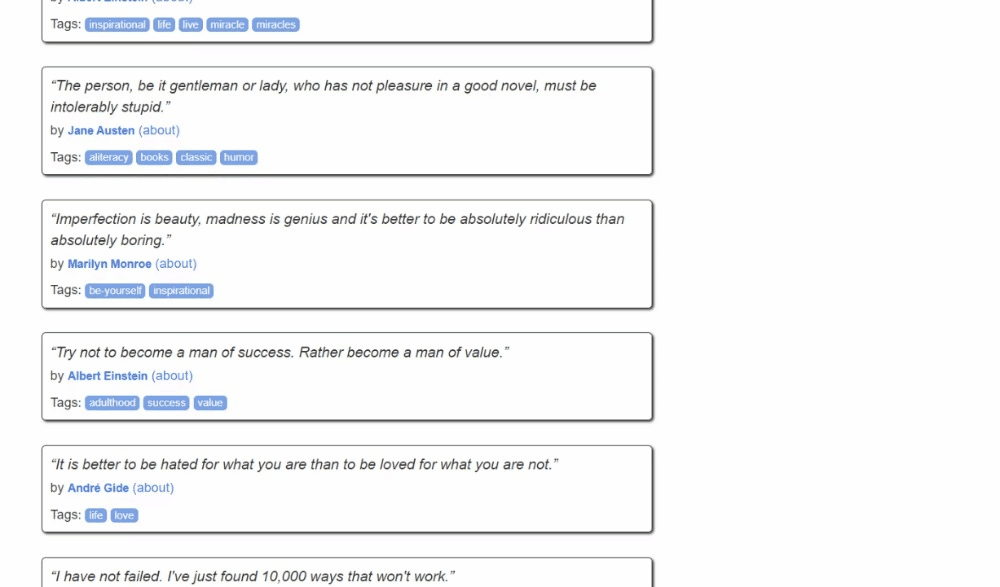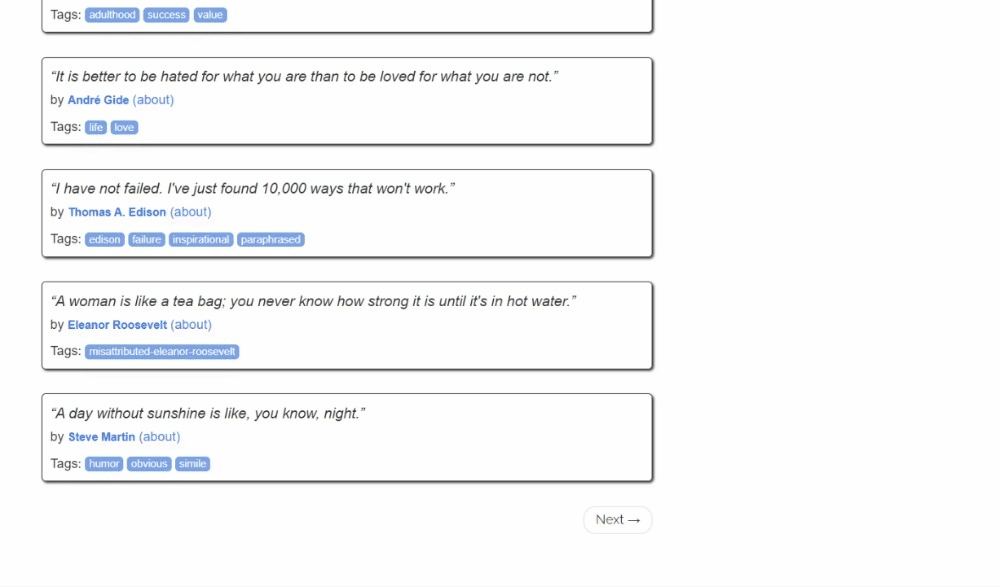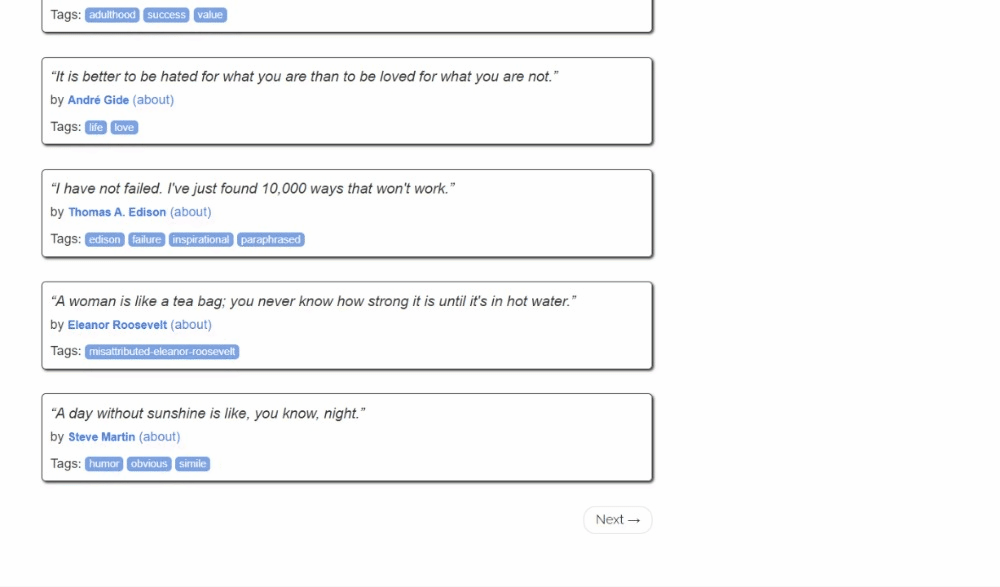
Follow the steps below and find out how to perform web scraping in Kotlin!
Step 1: Install the scraping library
The first thing to do is to figure out which Kotlin web scraping libraries are best suited to your goals. To do that, you must inspect the target site.
So, visit the Quotes To Scrape sandbox site in your browser. Right-click on a blank section, and select the “Inspect” option to open the DevTools. Reach the “Network” tab, reload the page, and explore the “Fetch/XHR” section.
This is what you should be seeing:

No AJAX requests! In other words, the target page does not retrieve data dynamically via JavaScript. This means that the server returns pages to clients with all the data of interest embedded in the HTML code.
Consequently, an HTML parsing library will do just fine. You can still use a browser automation tool, but loading and rendering the page in a browser would only introduce a performance overhead and no real benefit.
Thus, skrape{it} will be a great choice to achieve the web scraping goal. Add it to your project’s dependencies with this line in the dependencies object of your build.gradle.kts file:
implementation("it.skrape:skrapeit:1.2.2")Otherwise, if you are a Maven user, add these lines to the <dependencies> tag in your pom.xml:
<dependency>
<groupId>it.skrape</groupId>
<artifactId>skrapeit</artifactId>
<version>1.2.2</version>
</dependency>If you are using IntelliJ IDEA, the IDE will show a button to reload the project’s dependencies and install the new library. Click it to install skrape{it}.
Equivalently, you can manually install the new dependency with this Gradle command:
./gradlew build --refresh-dependenciesThe installation process may take a while, so be patient.
Next, get ready to use skrape{it} in your App.kt script by adding the following imports to it:
import it.skrape.core.*
import it.skrape.fetcher.*Do not forget that kkrape{it} comes with many data fetchers. Here, we imported them all for the sake of simplicity. At the same time, you will only need HttpFetcher, a classic HTTP client that sends an HTTP request to the given URL and returns a parsed response.
Awesome! You now have everything required to perform web scraping with Kotlin!
Step 2: Download the target page and parse its HTML
In App.kt, remove the App class and add the following lines in the main() function to connect to the target page using skrape{it}:
skrape(HttpFetcher) {
// make an HTTP GET request to the specified URL
request {
url = "https://quotes.toscrape.com/"
}
}Under the hood, skrape{it} will use the HttpFetcher class mentioned before to make a synchronous HTTP GET request to the given URL.
If you want to make sure the script is working as desired, add the following section in the skrape(HttpFetcher) definition:
response {
// get the HTML source code and print it
htmlDocument {
print(html)
}
}This tells skrape{it} what to do with the server response. Specifically, it accesses the parsed response and then prints the HTML code of the page.
Your App.kt Kotlin scraping script should now contain:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
fun main() {
skrape(HttpFetcher) {
// make an HTTP GET request to the specified URL
request {
url = "https://quotes.toscrape.com/"
}
response {
// get the HTML source code and print it
htmlDocument {
print(html)
}
}
}
}Execute the script and it will print:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omitted for brevity... -->That is exactly the HTML code of the target page. Well done!
Step 3: Inspect the page content
The next step would be to define the scraping logic. But how can you do that without knowing how to select the elements on the page? That is why it is important to take an extra step and inspect the structure of the target page.
Open Quotes To Scrape again in your browser. Right-click on one quote element and select “Inspect” to open the DevTools as below:

Here, you can notice that each quote card is a .quote HTML element that wraps:
- A .text element with the quote text.
- A .author element with the name of the author.
- Multiple .tag elements, each displaying a single tag.
Note that not all quotes have the tag section:

The CSS selectors above will help you select the desired DOM elements from the page to extract data from them. You will also need a class where to store this data. So, add the following Quote class definition on top of your web scraping Kotlin script:
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}Since the page contains several quotes, instantiate a List of Quote objects in main():
val quotes: MutableList<Quote> = ArrayList()At the end of the script, quotes will contain all the quotes collected from the site.
Use what you have understood and defined here to implement scraping logic in the next step!
Step 4: Implement the scraping logic
skrape{it} has a peculiar way of selecting HTML nodes on a page. To apply a CSS selector on the page, you need to define a section inside htmlDocument with the same name as the CSS selector:
skrape(HttpFetcher) {
// request section...
response {
htmlDocument {
// select all ".quote" HTML elements on the page
".quote" {
// scraping logic...
}
}
}
}Inside the “.quote” section, you can then define a findAll section. This will contain the logic that will be applied to each quote HTML node selected with the specified CSS selector. Instead, findFirst will get you only the first selected element.
Under the scenes, all these sections are nothing more than Kotlin lambda functions. Because of that, you can access the single DOM element with it in a forEach section inside findAll. If you are not familiar with that, it is the implicit name of a single parameter in a lambda.
it follows a similar logic, but based on methods and attributes. You can then implement scraping logic to extract the desired data from each quote, instantiate a Quote object, and add it to the quotes list as follows:
".quote" {
findAll {
forEach {
// scraping logic on a single quote element
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// create a Quote object and add it to the list
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}Thanks to the text attribute you can retrieve the inner text of an HTML element. Since not all quote HTML elements contain tags, you need to handle the ElementNotFoundException. This is raised by findAll when the given CSS selector does not match any node on the page.
Import ElementNotFoundException with:
import it.skrape.selects.ElementNotFoundException
Put all the snippets together and log the data contained in the quotes array:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
// define a class to represent the scraped data in Kotlin
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// where to store the scraped data
val quotes: MutableList<Quote> = ArrayList()
skrape(HttpFetcher) {
// make an HTTP GET request to the specified URL
request {
url = "https://quotes.toscrape.com/"
}
response {
htmlDocument {
// select all ".quote" HTML elements on the page
".quote" {
findAll {
forEach {
// scraping logic on a single quote element
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// create a Quote object and add it to the list
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
}
}
}
// log the scraped data
for (quote in quotes) {
println("Text: ${quote.text}")
println("Author: ${quote.author}")
println("Tags: ${quote.tags.joinToString("; ")}")
println()
}
}Note the use of joingToString() to merge the tags list into a comma-separated string.
If you execute the script, you will now get:
Text: “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
Author: Albert Einstein
Tags: change; deep-thoughts; thinking; world
# omitted for brevity...
Text: “A day without sunshine is like, you know, night.”
Author: Steve Martin
Tags: humor; obvious; simileWow! You just learned how to perform web scraping with Kotlin!
Step 5: Add the crawling logic
You just scraped data from a single page, but the list of quotes is spread over several pages. If you scroll down the page to the end, you will notice a “Next →” button with a link to the following page:

This is true for all pages except the last one:

To perform web crawling in Kotlin and scrape each quote on the site, you then need to:
- Scrape all quotes from the current page.
- Select the “Next →” element, if present, and extract the URL of the next page from it.
- Repeat the first step on the new page.
Implement the above algorithm as follows:
Instead of scraping a single page and then stopping, the script now relies on a while loop. This continues to iterate until there are no more pages to scrape. That happens when the .next a CSS selector raises an ElementNotFoundException exception, which means that the “Next →” button is not on the page and so you are on the last pagination page of the site.
Note that the htmlDocument section can contain multiple CSS selector sections. Each will be run in the specified order. If you launch the web scraping Kotlin script again, quotes will now store all 100 quotes on the site.
Wonderful! The Kotlin web scraping and crawling logic is ready. It only remains to remove the logging code with the data export logic.
Step 7: Export the scraped data to CSV
The collected data is currently stored in a list of Quote objects. Printing to the terminal is useful, but exporting to CSV is the best way to get the most out of it. This will enable other members of your team to filter, read, and analyze that data.
Kotlin provides you with everything you need to create a CSV file and populate it, but using a library makes everything easier. A popular Kotlin-native library to read and write CSV files is kotlin-csv.
Add it to your project’s dependencies in build.gradle.kts:
implementation("com.github.doyaaaaaken:kotlin-csv-jvm:1.9.3")Or if you are on Maven:
<dependency>
<groupId>com.github.doyaaaaaken</groupId>
<artifactId>kotlin-csv-jvm</artifactId>
<version>1.9.3</version>
</dependency>Install the library and import it in your App.kt file:
import com.github.doyaaaaaken.kotlincsv.dsl.*You can now export quotes to a CSV file with just a few lines of code:
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}Note that List<String> is how a CSV record is represented in kotlin-csv. First, define a record for the header row. Then, convert quotes to the desired data. Next, initialize a CSV writer, create a quotes.csv file, and populate it with writeRow() and writeRows().
Here we go! All that remains is to take a look at the final code of your Kotlin web scraping script.
Step 8: Put it all together
Here is the final code of your Kotlin scraper:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
import com.github.doyaaaaaken.kotlincsv.dsl.*
// define a class to represent the scraped data in Kotlin
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// where to store the scraped data
val quotes: MutableList<Quote> = ArrayList()
// the URL of the next page to visit
var nextUrl: String? = "https://quotes.toscrape.com/"
// until there is a page to visit
while (nextUrl != null) {
skrape(HttpFetcher) {
// make an HTTP GET request to the specified URL
request {
url = nextUrl!!
}
response {
htmlDocument {
// select all ".quote" HTML elements on the page
".quote" {
findAll {
forEach {
// scraping logic on a single quote element
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch (e: ElementNotFoundException) {
null
}
// create a Quote object and add it to the list
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
// crawling logic
try {
".next a" {
findFirst {
nextUrl = "https://quotes.toscrape.com" + attribute("href")
}
}
} catch (e: ElementNotFoundException) {
nextUrl = null
}
}
}
}
}
// create a "quotes.csv" file and populate it
// with the scraped data
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}
}Can you believe it? Thanks to skrape{it}, you can retrieve data from an entire site in less than 100 lines of code!
Run your web scraping Kotlin script with:
./gradlew runBe patient while the scraper goes through each page on the target site. When it is done, a quotes.csv file will appear in the root directory of your project. Open it and you should see the following data:

Et voilà! You started with unstructured data in online pages and now you have it in an easy-to-explore CSV file!
Avoid IP Bans in Kotlin with a Proxy
When performing web scraping with Kotlin, one of the biggest challenge is getting blocked by anti-bot technologies. These systems can detect the automated nature of your script and ban your IP. This way, they stop your scraping operation.
How to avoid that? With a web proxy!
Follow the step below and learn how to integrate a Bright Data proxy into Kotlin.
Set Up a Proxy in Bright Data
Bright Data is the best proxy server on the market, monitoring thousands of proxy servers around the world. When it comes to IP rotation, the best proxy type to go for is a residential proxy.
To get started, if you already have an account, log in to Bright Data. Otherwise, create an account for free. You will gain access to the following user dashboard:

Click the “View proxy products” button as below:

You will be redirected to the following “Proxies & Scraping Infrastructure” page:

Scroll down, find the “Residential Proxies” card, and click on the “Get started” button:

You will reach the residential proxy configuration dashboard. Follow the guided wizard and set up the proxy service based on your needs. If you have any doubts about how to configure the proxy, feel free to contact the 24/7 support.

Go to the “Access parameters” tab and retrieve your proxy’s host, port, username, and password as follows:

Note that the “Host” field already includes the port.
That is all you need to build the proxy URL and use it in skrape{it}. Put all the information together, and build a URL with the following syntax:
<Username>:<Password>@<Host>For example, in this case it would be:
brd-customer-hl_4hgu8dwd-zone-residential:[email protected]:XXXXXToggle “Active proxy,” follow the last instructions, and you are ready to go!

Integrate the Proxy in Kotlin
The snippet for Bright Data integration in skrape{it} will look like as follows:
skrape(HttpFetcher) {
request {
url = "https://quotes.toscrape.com/"
proxy = proxyBuilder {
type = Proxy.Type.HTTP
host = "brd.superproxy.io"
port = XXXXX
}
authentication = basic {
username = "brd-customer-hl_4hgu8dwd-zone-residential"
password = "ZZZZZZZZZZ"
}
}
// ...
}As you can see, it all boils down to using the proxy and authentication request options. From now on, skrape{it} will make the request to the specified URL therough the Bright Data proxy. Bye bye IP bans!
Keep Your Kotlin Web Scraping Operation Ethical and Respectful
Scraping the Web is an effective way to collect useful data for various use cases. Bear in mind that the end goal is to retrieve that data, not to damage the target site. Therefore, you must approach this task with the right precautions.
Follow the tips below to perform responsible Kotlin web scraping:
- Target only publicly available information: Focus on retrieving data that is publicly accessible on the site. Avoid instead pages that are protected by login credentials or other forms of authorization. Scraping private or sensitive data without proper permission is unethical and may lead to legal consequences.
- Respect the robots.txt file: Every site has a robots.txt file that defines the rules on how automated crawlers should access its pages. To maintain ethical scraping practices, you must adhere to those guidelines. Find out more in our robots.txt for web scraping guide.
- Limit the frequency of your requests: Making too many requests in a short time will lead to a server overload, affecting site performance for all users. That might also trigger rate limiting measures and get you blocked. For this reason, avoid flooding the destination server by adding random delays to your requests.
- Check and comply with the site’s Terms of Service: Before scraping a site, review its Terms of Service. These may contain information on copyright, intellectual property rights, and guidelines on how and when to use their data.
- Rely on trustworthy and up-to-date scraping tools: Select reputable providers and opt for tools and libraries that are well-maintained and regularly updated. Only then can you ensure that they are in line with the latest ethical Kotlin scraping principles. If you have any doubts, check out our article on how to choose the best web scraping service.
Conclusion
In this guide, you saw why Kotlin is a great language for web scraping, especially when compared to Java. You also saw a list of the best Kotlin scraping libraries. Then, you learned how to use skrape{it} to build a scraper that extracts data from multiple pages of a real-world site. As you experienced here, web scraping with Kotlin is simple and takes only a few lines of code.
The main challenge to your scraping operation is anti-bot solutions. Websites adopt these systems to protect their data from automated scripts, blocking them before they can access their pages. Getting around them all is not easy and requires advanced tools. Fortunately, Bright Data has you covered!
These are some of the scraping products offered by Bright Data:
- Web Scraper API: Easy-to-use APIs for programmatic access to structured web data from dozens of popular domains.
- Scraping Browser: A cloud-based controllable browser that offers JavaScript rendering capabilities while handling browser fingerprinting, CAPTCHAs, automated retries, and more for you. It integrates with the most popular automation browser libraries, such as Playwright and Puppeteer.
- Web Unlocker: An unlocking API that can seamlessly return the raw HTML of any page, circumventing any anti-scraping measures.
Don’t want to deal with web scraping at all but are still interested in online data? Explore Bright Data’s ready-to-use datasets!

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



