

In this tutorial, you will understand why Go is one of the best languages for scraping the web efficiently and learn how to build a Go scraper from scratch.
This article will cover:
- Can you perform web scraping with Go?
- Best Go web scraping libraries
- Build a web scraper in Go
Can You Perform Web Scraping With Go?
Go, also known as Golang, is a statically-typed programming language created by Google. It is designed to be efficient, concurrent, and easy to write and maintain. These characteristics have recently made Go a popular choice in several applications, including web scraping.
In detail, Go provides powerful features that come in handy when it comes to web scraping tasks. These include its built-in concurrency model, which supports the concurrent processing of multiple web requests. This makes Go the ideal language for scraping large amounts of data from multiple websites efficiently. Also, Go’s standard library includes HTTP client and HTML parsing packages that can be used to fetch web pages, parse HTML, and extract data from websites.
If those capabilities and default packages were not enough or too difficult to use, there are also several Go web scraping libraries. Let’s take a look at the most popular ones!
Best Go Web Scraping Libraries
Here is a list of some of the best web scraping libraries for Go:
- Colly: A powerful web scraping and crawling framework for Go. It provides a functional API for making HTTP requests, managing headers, and parsing the DOM. Colly also supports parallel scraping, rate limiting, and automatic cookie handling.
- Goquery: A popular HTML parsing library in Go based on a jQuery-like syntax. It allows you to select HTML elements through CSS selectors, manipulate the DOM, and extract data from them.
- Selenium: A Go client of the most popular web testing framework. It enables you to automate web browsers for various tasks, including web scraping. Specifically, Selenium can control a web browser and instruct it to interact with pages as a human user would. It is also able to perform scraping on web pages that use JavaScript for data retrieval or rendering.
Prerequisites
Before getting started, you need to install Go on your machine. Note that the installation procedure changes based on the operating system.
Set up Go on macOS
- Download Go.
- Open the downloaded file and follow the installation prompts. The package will install Go to /usr/local/go and add /usr/local/go/bin to your PATH environment variable.
- Restart any open Terminal sessions.
Set up Go on Windows
- Download Go.
- Launch the download MSI file you downloaded and follow the installation wizard. The installer will install Go to C:/Program Files or C:/rogram Files (x86) and add the bin folder to the PATH environment variable.
- Close and reopen any command prompts.
Set up Go on Linux
- Download Go.
- Make sure your system does not have a /usr/local/go folder. If it exists, delete it with:
rm -rf /usr/local/go- Extract the downloaded archive into /usr/local:
tar -C /usr/local -xzf goX.Y.Z.linux-amd64.tar.gzMake sure to replace X.Y.Z with the version of the Go package you downloaded.
- Add /usr/local/go/bin to the PATH environment variable:
export PATH=$PATH:/usr/local/go/bin- Reload your PC.
Regardless of your OS, verify that Go has been installed successfully with the command below:
go versionThis will return something like:
go version go1.20.3Well, done! You are now ready to jump into Go web scraping!
Build a Web Scraper in Go
Here, you will learn how to build a Go web scraper. This automated script will be able to automatically retrieve data from the Bright Data home page. The goal of the Go web scraping process will be to select some HTML elements from the page, extract data from them, and convert the collected data to an easy-to-explore format.
At the time of writing, this is what the target site looks like:

Follow the step-by-step tutorial and learn how to perform web scraping in Go!
Step 1: Set up a Go project
Time to initialize your Go web scraper project. Open the terminal and create a go-web-scraper folder:
mkdir go-web-scraperThis directory will contain the Go project.
Next, run the init command below:
go mod init web-scraperThis will initialize a web-scraper module inside the project root.
The go-web-scraper directory will now contain the following go.mod file:
module web-scraper
go 1.20Note that the last line changes depending on your version of Go.
You are now ready to start writing some Go logic in your IDE! In this tutorial, we are going to use Visual Studio Code. Since it does not support Go natively, you first need to install the Go extension.
Launch VS Code, click on the “Extensions” icon on the left bar, and type “Go.”

Click the “Install” button on the first card to add the Go for Visual Studio Code extension.
Click on “File,” select “Open Folder…,” and open the go-web-scraper directory.
Right-click on the “Explorer” section, select “New File…,” and create a scraper.go file as follows:
// scraper.go
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello, World!")
}Keep in mind that the main() function represents the entry point of any Go app. This is where you will have to place your Golang web scraping logic.
Visual Studio Code will ask you to install some packages to complete the integration with Go. Install them all. Then, run the Go script by launching the command below in the VS Terminal:
go run scraper.go

This will print:
Hello, World!Step 2: Get started with Colly
To build a web scraper to Go more easily, you should use one of the packages presented earlier. But first, you need to figure out which Golang web scraping library best fit your goals. To do so, visit the target website, right-click on the background, and select the “Inspect” option. This will open your browser’s DevTools. In the “Network” tab, take a look at the “Fetch/XHR” section.

As you can see above, the target web page performs only a few AJAX requests. If you explore each XHR request, you will notice that they do not return any meaningful data. In other words, the HTML document returned by the server already contains all the data. This is what generally happens with static content sites.
That shows that the target site does not rely on JavaScript to dynamically retrieve data or for rendering purposes. As a result, you do not need a library with headless browser capabilities to retrieve data from the target web page. You can still use Selenium, but that would only introduce a performance overhead. For this reason, you should prefer a simple HTML parser such as Colly.
Add Colly to your project’s dependencies with:
go get github.com/gocolly/collyThis command creates a go.sum file and updates the go.mod file accordingly.
Before starting to use it, you need to dig into some key Colly concepts.
Colly’s main entity is the Collector. This object allows you to perform HTTP requests and perform web scraping via the following callbacks:
- OnRequest(): Called before making any HTTP request with Visit().
- OnError(): Called if an error occurs in an HTTP request.
- OnResponse(): Called after getting a response from the server.
- OnHTML(): Called after OnResponse(), if the server returned a valid HTML document.
- OnScraped(): Called after all OnHTML() calls ended.
Each of these functions takes a callback as a parameter. When the event associated with the function is raised, Colly executes the input callback. So, to build a data scraper in Colly, you need to follow a functional approach based on callbacks.
You can initialize a Collector object with the NewCollector() function:
c := colly.NewCollector()
Import Colly and create a Collector by updating scraper.go as follows:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// scraping logic...
}Step 3: Connect to the target website
Use Colly to connect to the target page with:
c.Visit("https://brightdata.com/")Behind the scene, the Visit() function performs an HTTP GET request and retrieves the target HTML document from the server. In detail, it fires the onRequest event and starts the Colly functional lifecycle. Keep in mind that Visit() must be called after registering the other Colly callbacks.
Note that the HTTP request made by Visit() can fail. When this happens, Colly raises the OnError event. The reasons for failure can be anything from a temporarily unavailable server to an invalid URL. At the same time, web scrapers generally fail when the target site adopts anti-bot measures. For example, these technologies generally filter out requests that do not have a valid User-Agent HTTP header. Check out our guide to find out more about User-Agents for web scraping.
By default, Colly sets a placeholder User-Agent that does not match the agents used by popular browsers. This makes Colly requests easily identifiable by anti-scraping technologies. To avoid being blocked because of that, specify a valid User-Agent header in Colly as below:
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36Any Visit() call will now perform a request with that HTTP header.
Your scraper.go file should now look like as follows:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// connect to the target site
c.Visit("https://brightdata.com/")
// scraping logic...
}Step 4: Inspect the HTML page
Let’s analyze the DOM of the target Web page to define an effective data retrieval strategy.
Open Bright Data homepage in your browser. If you take a look at it, you will notice a list of cards with the industries where Bright Data’s services can provide a competitive advantage. That is interesting info to scrape.
Right-click one of these HTML cards and select “Inspect”:

In the DevTools, you can see the HTML code of the selected node in the DOM. Note that each industry card is an <a> HTML element. Specifically, each <a> contains the following two key HTML elements:
- A <figure> storing the image in the industry card.
- A <div> presenting the name of the industry field.
Now, focus on the CSS classes used by the HTML elements of interest and their parents. Thanks to them, you will be able to define the CSS selector strategy required to get the desired DOM elements.
In detail, each card is characterized by the section_cases__item class and is contained in the .elementor-element-6b05593c <div>. Thus, you can get all industry cards with the following the CSS selector:
.elementor-element-6b05593c .section_cases__itemGiven a card, you can then select its <figure> and <div> relevant children with:
.elementor-image-box-img img
.elementor-image-box-content .elementor-image-box-titleThe scraping goal of the Go scraper is to extract the URL, image, and industry name from each card.
Step 5: Select HTML elements with Colly
You can apply a CSS or XPath selector in Colly as follows:
c.OnHTML(".your-css-selector", func(e *colly.HTMLElement) {
// data extraction logic...
})Colly will call the function passed as a parameter for each HTML element that matches the CSS selector. In other terms, it automatically iterates over all selected elements.
Do not forget that a Collector can have multiple OnHTML() callbacks. These will be run in the order the onHTML() instructions appear in the code.
Step 6: Scrape data from a webpage with Colly
Learn how to use Cooly to extract the desired data from the HTML webpage.
Before writing the scraping logic, you need some data structures where to store the extracted data. For example, you can use a Struct to define an Industry data type as follows:
type Industry struct {
Url, Image, Name string
}In Go, a Struct specifies a set of typed fields that can be instantiated as an object. If you are familiar with object-oriented programming, you can think of a Struct as sort of a class.
Then, you will need a slice of type Industry:
var industries []IndustryGo slices are nothing more than lists.
Now, you can use the OnHTML() function to implement the scraping logic as below:
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url!= "" || image != "" || name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})The web scraping Go snippet above selects all industry cards from the Bright Data homepage and iterates over them. Then, it populates by scraping the URL, image, and industry name associated with each card. Finally, it instantiates a new Industry object and adds it to the industries slice.
As you can see, running scraping in Colly is simple. Thanks to the Attr() method, you can extract an HTML attribute from the current element. Instead, ChildAttr() and ChildText() give you to attribute value and text of an HTML child selected through a CSS selector.
Keep in mind that you can also collect data from industry detail pages. All you have to do is follow the links discovered on the current page and implement new scaping logic accordingly. This is what web crawling and web scraping are all about!
Well done! You just learned how to achieve your goals in web scraping using Go!
Step 7: Export the extracted data
After the OnHTML() instruction, industries will contain the scraped data in Go objects. To make the data extracted from the web more accessible, you need to convert it to a different format. See how to export the scraped data to CSV and JSON.
Note that Go’s standard library comes with advanced data exporting capabilities. You do not need any external package to convert the data to CSV and JSON. All you need to do is make sure that your Go script contains the following imports:
- For CSV export:
import (
"encoding/csv"
"log"
"os"
)
- For JSON export:
import (
"encoding/json"
"log"
"os"
)You can export the industries slice to a industries.csv file in Go as follows:
// open the output CSV file
file, err := os.Create("industries.csv")
// if the file creation fails
if err != nil {
log.Fatalln("Failed to create the output CSV file", err)
}
// release the resource allocated to handle
// the file before ending the execution
defer file.Close()
// create a CSV file writer
writer := csv.NewWriter(file)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}The snippet above creates a CSV file and initializes it with the header row. Then, it iterates over the slice of Industry objects, converts each element to a slice of strings, and appends it to the output file. The Go CSV Writer will automatically convert the list of strings to a new record in CSV format.
Run the script with:
go run scraper.goAfter its execution, you will notice a industries.csv file in the root folder of your Go project. Open it and you should see the following data:
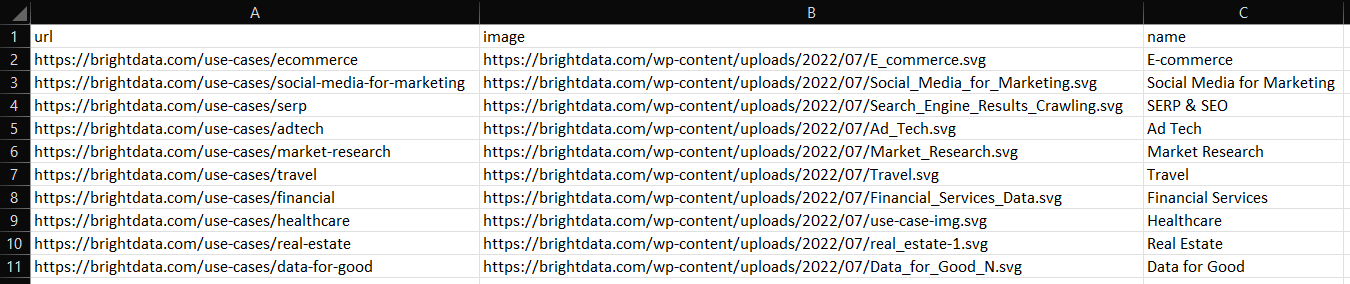
Similarly, you can export industries to industry.json as below:
file, err:= os.Create("industries.json")
if err != nil {
log.Fatalln("Failed to create the output JSON file", err)
}
defer file.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
file.Write(jsonString)
This will produce the JSON file below:
[
{
"Url": "https://brightdata.com/use-cases/ecommerce",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"Name": "E-commerce"
},
// ...
{
"Url": "https://brightdata.com/use-cases/real-estate",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/real_estate-1.svg",
"Name": "Real Estate"
},
{
"Url": "https://brightdata.com/use-cases/data-for-good",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"Name": "Data for Good"
}
]Et voila! Now you know how to transfer the collected data into a more useful format!
Step 8: Put it all together
Here is what the full code of the Golang scraper looks like:
// scraper.go
package main
import (
"encoding/csv"
"encoding/json"
"log"
"os"
// import Colly
"github.com/gocolly/colly"
)
// definr some data structures
// to store the scraped data
type Industry struct {
Url, Image, Name string
}
func main() {
// initialize the struct slices
var industries []Industry
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url != "" && image != "" && name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
// connect to the target site
c.Visit("https://brightdata.com/")
// --- export to CSV ---
// open the output CSV file
csvFile, csvErr := os.Create("industries.csv")
// if the file creation fails
if csvErr != nil {
log.Fatalln("Failed to create the output CSV file", csvErr)
}
// release the resource allocated to handle
// the file before ending the execution
defer csvFile.Close()
// create a CSV file writer
writer := csv.NewWriter(csvFile)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
// --- export to JSON ---
// open the output JSON file
jsonFile, jsonErr := os.Create("industries.json")
if jsonErr != nil {
log.Fatalln("Failed to create the output JSON file", jsonErr)
}
defer jsonFile.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
jsonFile.Write(jsonString)
}In less than 100 lines of code, you can build a data scraper in Go!
Conclusion
In this tutorial, you saw why Go is a good language for web scraping. Also, you realized what the best Go scraping libraries are and what they offer. Then, you learned how to use Colly and Go’s standard library to create a web scraping application. The Go scraper built here can scrape data from a real-world target. As you saw, web scraping with Go takes only a few lines of code.
At the same time, keep in mind there are many challenges to take into account when extracting data from the Internet. This is why many websites adopt anti-scraping and anti-bot solutions that can detect and block your Go scraping script. Bright Data offers different solutions, contact us to find the perfect solution for your use case.
Don’t want to deal with web scraping at all but are interested in web data? Explore our ready-to-use datasets.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



