

As the amount of data on the internet continues to grow, web crawling, the process of automatically navigating and extracting information from websites, becomes an increasingly important skill for developers to learn. This is done by sending HTTP requests to web servers and parsing the HTML response to extract the desired data.
The web crawling process can be complex and time-consuming; however, the right tools and techniques can help. With its flexibility and ease of use, Python has emerged as a popular language for building web crawlers, allowing developers to quickly write scripts to automate the data extraction process.
In this article, you’ll learn all about web crawling with Python using the Scrapy library.
Why You Need Web Crawling
Before we dive into the tutorial, it’s important to acknowledge the difference between web scraping and web crawling. While similar, web scraping extracts specific data from web pages, whereas web crawling browses web pages for indexing and gathers information for search engines.
Web crawling is useful in all kinds of scenarios, including the following:
- Data extraction: Web crawling can be used to extract specific pieces of data from websites, which can then be used for analysis or research.
- Website indexing: Search engines often use web crawling to index websites and make them searchable for users.
- Monitoring: Web crawling can be used to monitor websites for changes or updates. This information is often useful in tracking competitors.
- Content aggregation: Web crawling can be used to collect content from multiple websites and aggregate it into a single location for easy access.
- Security testing: Web crawling can be used for security testing to identify vulnerabilities or weaknesses in websites and web applications.
Web Crawling with Python
Python is a popular choice for web crawling due to its ease of use in coding and intuitive syntax. Additionally, Scrapy, one of the most popular web crawling frameworks, is built on Python. This powerful and flexible framework makes it easy to extract data from websites, follow links, and store the results.
Scrapy is designed to handle large amounts of data and can be used for a wide range of web scraping tasks. The tools included in Scrapy, such as the HTTP downloader, spider for crawling websites, scheduler for managing crawling frequency, and item pipeline for processing scraped data, make it well-suited for various web crawling tasks.
To get started with web crawling using Python, you need to install the Scrapy framework on your system.
Open your terminal and run the following command:
pip install scrapyn
After running this command, you will have scrapy installed in your system. Scrapy provides you with classes called spiders that define how to perform a web crawling task. These spiders are responsible for navigating the website, sending requests, and extracting data from the website’s HTML.
Creating a Scrapy Project
In this article, you’re going to crawl a website called Books to Scrape and save the name, category, and price of each book in a CSV file. This website was created to work as a sandbox for scraping projects.
Once Scrapy is installed, you need to create a new project structure using the following command:
scrapy startproject bookcrawlern
(note: If you get a ”command not found” error, restart your terminal)
The default directory structure provides a clear and organized framework, with separate files and directories for each component of the web scraping process. This makes it easy to write, test, and maintain your spider code, as well as process and store the extracted data in whatever way you prefer. This is what your directory structure looks like:
bookcrawlernâ scrapy.cfgnânââââbookcrawlern â items.pyn â middlewares.pyn â pipelines.pyn â settings.pyn â __init__.pyn ân ââââspidersn __init__.pynn
To initiate the crawling process in your Scrapy project, it’s essential to create a new spider file in the bookcrawler/spiders directory because it’s the standard directory where Scrapy looks for any spiders to execute the code. To do so, navigate to the bookcrawler/spiders directory and create a new file named bookspider.py. Then write the following code into the file to define your spider and specify its behavior:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]n rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/')),n )nn
This code defines a BookCrawler, which is subclassed from the built-in CrawlSpider, and provides a convenient way to define rules for following links and extracting data. The start_urls attribute specifies a list of URLs to start crawling from. In this case, it contains only one URL, which is the home page of the website.
The rules attribute specifies a set of rules to determine which links the spider should follow. In this case, there is only one rule defined, which is created using the Rule class from the scrapy.spiders module. The rule is defined with a LinkExtractor instance that specifies the pattern of links that the spider should follow. The allow parameter of the LinkExtractor is set to /catalogue/category/books/, which means that the spider should only follow links that contain this string in their URL.
To run the spider, open your terminal and run the following command:
scrapy crawl bookspidern
As soon as you run this, Scrapy initializes the spider class BookCrawler, creates a request for each URL in the start_urls attribute, and sends them to the Scrapy scheduler. When the scheduler receives a request, it checks if the request is allowed by the spider’s allowed_domains (if specified) attribute. If the domain is allowed, the request is then passed to the downloader, which makes an HTTP request to the server and retrieves the response.
At this point, you should be able to see every URL your spider has crawled in your console window:

The initial crawler that was created only performs the task of crawling a predefined set of URLs without extracting any information. To retrieve data during the crawling process, you need to define a parse_item function within the crawler class. The parse_item function is tasked with receiving the response from each request made by the crawler and returning relevant data obtained from the response.
Please note: The
parse_itemfunction only works after setting thecallbackattribute in yourLinkExtractor.
To extract data from the response obtained by crawling web pages in Scrapy, you need to use CSS selectors. The next section provides a brief introduction to CSS selectors.
A Bit about CSS Selectors
CSS selectors are a way to extract data from the web page by specifying tags, classes, and attributes. For instance, here is a Scrapy shell session that has been initialized using scrapy shell books.toscrape.com:
# check if the response was successfulnu003eu003eu003e responsenu003c200 http://books.toscrape.comu003enn#extract the title tagnu003eu003eu003e response.css('title')n[u003cSelector xpath='descendant-or-self::title' data='u003ctitleu003e
All products | Books to S...'u003e]n
In this session, the css function takes a tag (ie title) and returns the Selector object. To get the text within the title tag, you have to write the following query:
u003eu003eu003e print(response.css('title::text').get())n All products | Books to Scrape - Sandboxn
In this snippet, the text pseudo selector is used in order to remove the enclosing title tag and returns only the inner text. The get method is used to display only the data value.
In order to get the classes of the elements, you need to view the source code of the page by right-clicking and selecting Inspect:
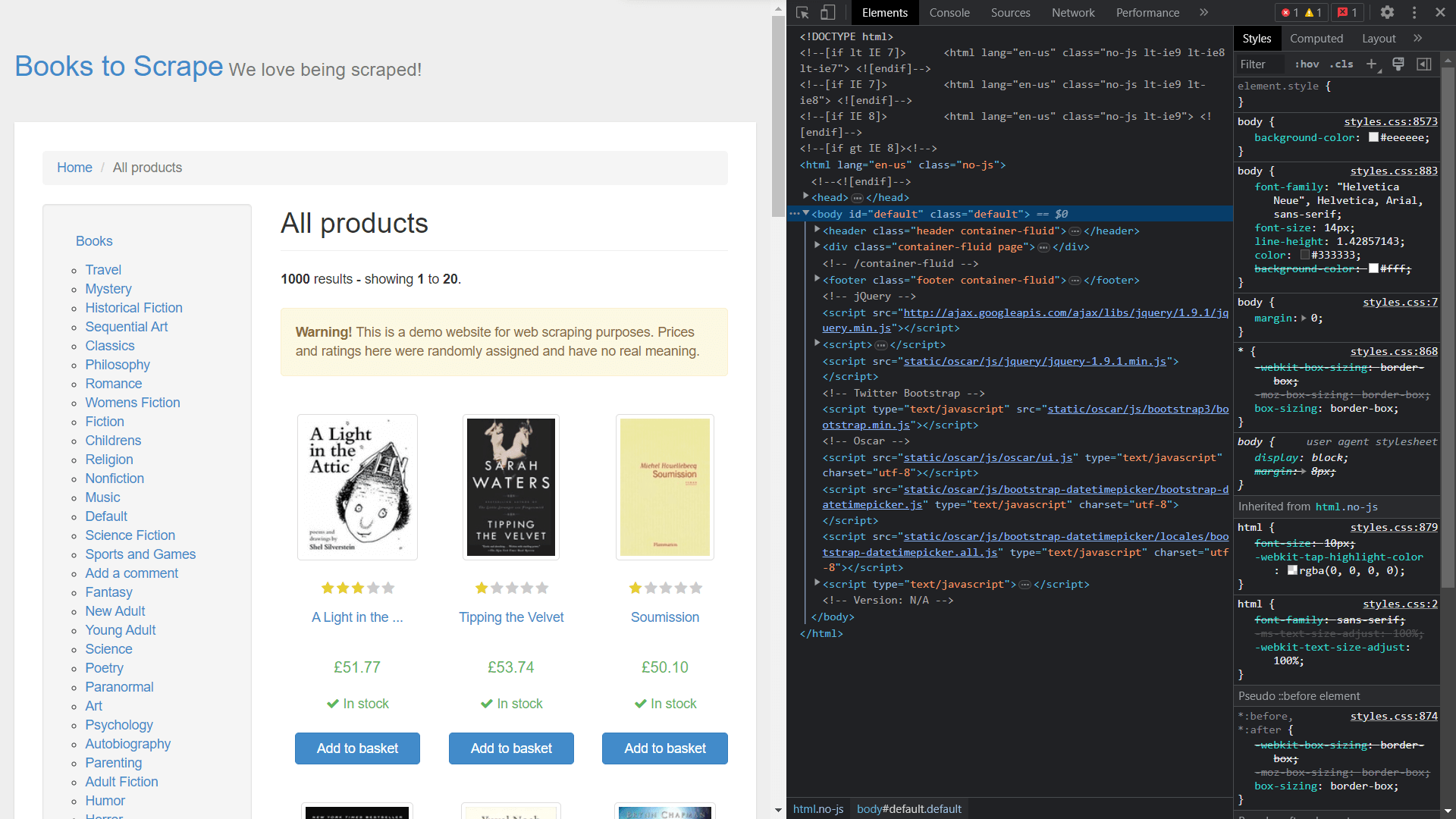
Extracting Data Using Scrapy
To extract elements from the response object, you need to define a callback function and assign it as an attribute in the Rule class.
Open bookspider.py and run the following code:
from scrapy.spiders import CrawlSpider, Rulenfrom scrapy.linkextractors import LinkExtractornnclass BookCrawler(CrawlSpider):n name = 'bookspider'n start_urls = [n 'https://books.toscrape.com/',n ]nnn rules = (n Rule(LinkExtractor(allow='/catalogue/category/books/'), callback=u0022parse_itemu0022), n n )n def parse_item(self, response):n category = response.css('h1::text').get()n book_titles = response.css('article.product_pod').css('h3').css('a::text').getall()n book_prices = response.css('article.product_pod').css('p.price_color::text').getall()n yield {n u0022categoryu0022: category,n u0022booksu0022:list(zip(book_titles,book_prices))n }nn
The parse_item function in the BookCrawler class contains the logic for the data to be extracted and yields it to the console. Using yield allows Scrapy to process the data in the form of items, which can then be passed through item pipelines for further processing or storage.
The process of selecting the category is a straightforward task since it’s coded within a simple <h1> tag. However, the selection of book_titles is achieved through a multilevel selection process, where the first step involves selecting the <article> tag with class product_pod. Following this, the traversal process continues to identify the <a> tag nested within the <h3> tag. The same approach is taken when selecting book_prices, enabling the retrieval of the necessary information from the web page.
At this point, you’ve created a spider that crawls a website and retrieves data. To run the spider, open the terminal and run the following command:
scrapy crawl bookspider -o books.jsonn
When executed, the web pages crawled by the crawler and their corresponding data are displayed on the console. The usage of the -o flag instructs Scrapy to store all the retrieved data in a file named books.json. Upon completion of the script, a new file named books.json is created in the project directory. This file contains all the book-related data retrieved by the crawler:

It’s important to note that this web crawler is only effective for websites that do not employ IP blocking mechanisms in response to multiple requests. For sites that are less accommodating to web bots and crawlers, a proxy service such as Bright Data is necessary to extract data at scale. Bright Data’s services enable users to collect web data from multiple sources while avoiding IP blocks and detection.
Conclusion
Web crawling, integrated with web scraping, is a highly valuable skill for data collection and data science. Scrapy, a framework designed for web crawling, simplifies the process by offering built-in crawlers and scrapers.
This article walked you through building a web crawler and then scraping data using the Scrapy framework. You learned how to use CrawlSpider for effortless web crawling and learned about concepts like Rule and LinkExtractor to crawl specific patterns of URLs. Additionally, you covered the concepts of selecting HTML elements using CSS selectors. By mastering these skills, you will be well-equipped to tackle web crawling and web scraping challenges in data science and beyond.





