
Simply put, bad data refers to incomplete, inaccurate, inconsistent, irrelevant, or duplicate data that sneaks into your data infrastructure due to a variety of reasons.
By the end of this article, you will understand:
- What bad data is
- Various types of bad data
- What causes bad data
- Its consequences and preventive measures
So, let’s take a look at this further:
Different Types of Bad Data
Data quality and reliability are essential in almost every domain, from business analysis to AI model training. Poor quality data manifests in several different forms, each posing unique challenges to data usability and integrity.

Incomplete Data
Incomplete data refers to when a dataset lacks one or more of the attributes, fields, or entries necessary for accurate analysis. This missing information renders the entire dataset unreliable and sometimes even unusable.
Common causes for incomplete data include intentional omission of specific data, unrecorded transactions, partial data collection, mistakes during data entry, unseen technical issues during data transfer, etc.
For example, consider a situation where a customer survey is missing records of the contact details. That makes it impossible to follow up with the respondents later on, as shown below.

Another example can be a hospital database with medical records of patients lacking crucial information such as allergies and previous medical history can even lead to life-threatening situations.
Duplicate Data
Duplicate data occurs when the same data entry or nearly identical data entries are recorded multiple times within the database. This redundancy leads to misleading analytics and incorrect conclusions and sometimes complicates merge operations and system glitches. The statistics derived from a dataset with duplicate data become unreliable and inefficient for decision-making.
Examples:
- A customer relationship management (CRM) database with multiple records for the same customer can distort the information derived after analysis, such as the number of distinct customers or the sales per customer.
- An inventory management system storing the same product under different SKU numbers renders estimations about stocks inaccurate.
Inaccurate Data
Having incorrect, erroneous information within one or more dataset entries is identified as having inaccurate data.
A simple mistake in a code or a number due to a typographical error or an unintentional oversight can be serious enough to cause severe complications and losses, primarily when the data is used for decision-making in a high-stakes domain. The existence of inaccurate data itself diminishes the trustworthiness and the reliability of the whole dataset.
Examples:
- A shipping company database storing incorrect shipping addresses for deliveries might end up sending packages to the wrong locations, even the wrong countries, causing huge losses and delays for both the company and the customer.
- Situations in which a human resource management system (HRMS) contains incorrect information about employee salaries can cause payroll discrepancies and potential legal issues.
Inconsistent Data
Inconsistent data, which occurs when different people or teams use varying units or formats for the same type of data within an organization, is a common cause of confusion and inefficiency you might come across when working with data. It interrupts the uniformity and continuous flow between data, resulting in faulty data processing.
Examples:
- Inconsistent date formats across multiple data entries (MM/DD/YYYY vs DD/MM/YYYY), for instance, in a banking system, can cause conflicts and issues during data aggregation and analysis.

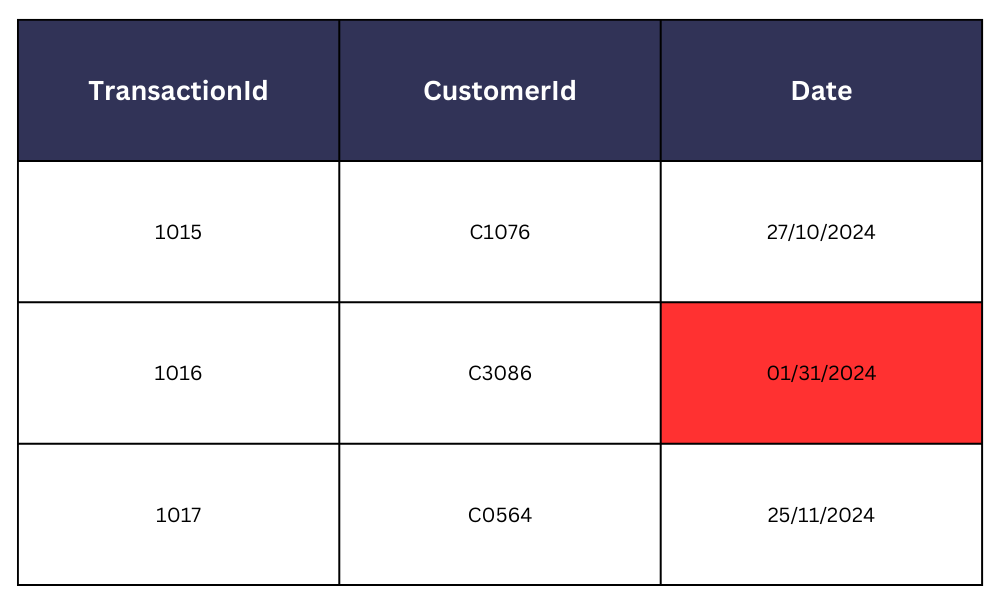
- Two stores of the same retail chain entering data about stocks in different units of measurement (number of cases vs number of individual items) can cause confusion when re-stocking and distributing.
Outdated Data
Simply put, outdated data are records that are no longer current, relevant, and applicable. Especially in fast-moving domains, outdated data is quite common, with rapid changes occurring continuously. Data from a decade, a year, or even a month ago can be no longer useful, even misleading, based on the context.
Examples:
- A person can develop new allergies over time. A hospital prescribing drugs to a patient with records of outdated allergy information can compromise the patient’s safety.
- A real estate agency listing properties from an outdated data source can be wasting time and effort over already sold out or no longer available properties. It is unproductive and can diminish the company’s reputation.
Furthermore, non-compliant, irrelevant, unstructured, and biased data are also types of bad data that can compromise the data quality in your data ecosystem. Understanding each of these various bad data types is essential for realizing their root causes and the threats they pose to your business and for devising strategies to mitigate the impact.
What Causes Bad Data
Now that you have a clear understanding of the types of bad data. It’s important to understand what causes it, so that you can take proactive measures to prevent such occurrences from happening in your datasets.
Some ways that can cause bad data includes:
- Human errors during data entry: It goes without saying that this is the most common cause of bad data, especially when incomplete, inaccurate, and duplicate data are concerned. Insufficient training, lack of attention to detail, misunderstandings about the data entry process, and mostly unintentional mistakes such as typos can ultimately lead to unreliable datasets and huge complications during analysis.
- Poor data entry practices and standards: A robust set of standards is the key to building solid and well-structured practices. For instance, if you allow free-text inputs for a field such as country, a user can enter different names for the same country (example: USA, United States, U.S.A.), resulting in an inefficiently wide variety of responses for the same value. Such inconsistencies and confusion arise as a result of not having properly set standards.
- Migration issues: Bad data is not always the result of manual inputs. It can also occur as a result of migrating data from one database to another. Such an issue causes misalignment of records and fields, data loss, and even data corruption that may require long hours of reviewing and fixing.
- Data degradation: Every small change occurring, from customer preferences to a shift in market trends, can update the company data. If the database is not updated constantly to match these changes, it becomes outdated data, causing data decay or data degradation. Outdated data has no real usage in decision-making and analysis and contributes to misleading information when used.
- Merging data from multiple sources: Inefficiently combining data from multiple sources or faulty data integration can result in inaccurate and inconsistent data. It happens when the different sources of data being combined are formatted into varying standards, formats, and quality levels.

Impact of Bad Data
If you process datasets that have bad data, you put your end analysis at risk. In fact, bad data can have long-lasting and devastating impacts, especially on data-driven businesses and domains; such as:
- Poor data quality can hurt your business by increasing the risk of making bad decisions and investments based on misleading information.
- Bad data causes substantial financial costs, including wasted resources and lost revenue. Recovering from the effects bad data has left behind can take a lot of funds and time.
- The accumulation of bad data can even cause business failure, as it increases the need for rework, leads to missed opportunities, and negatively impacts productivity as a whole.
- As a result, the trustworthiness and reliability of the business diminish, significantly hurting customer satisfaction and retention. Inaccurate and incomplete data from the company’s end leads to poor customer service and inconsistent communication.
In addition, bad data can lead to critical errors that accelerate into legal or life-threatening complications, especially in the financial and healthcare domains.
For instance, in 2020, during the COVID-19 pandemic, Public Health England (PHE) experienced a significant data management error that resulted in 15,841 COVID-19 cases going unreported due to bad data. The issue was traced back to the outdated version of Excel spreadsheets PHE was using, which could only hold up to 65,000 rows, rather than the million plus rows it could actually hold. Some of the records provided by the third-party firms analyzing swab tests were lost, causing incomplete data. The number of missed close contacts with infection risk due to this technical error was about 50,000.
Additionally, Samsung’s fat-finger error that occurred in 2018 ended up dropping the stock prices by around 11% within a single day, extinguishing nearly $300 million of market value. It was caused by a Samsung Securities employee because of a data entry mistake when he entered 2.8 billion “shares” (worth $105 billion) instead of 2.8 billion “South Korean Won” to be distributed among employees who took part in the company stock ownership plan.
Therefore, the consequences of bad data should not be taken lightly, and proper preventive measures must be taken to eliminate the risk.
Preventing Bad Data
No dataset is perfect. Your data is bound to have errors. The first step to preventing bad data is acknowledging this reality so that you can implement necessary preventive strategies to ensure data quality.
Some steps to prevent bad data includes:
- Implementing robust data governance is a crucial step in setting up accountability and standards across the organization. It can help you set up clear policies and procedures on how to manage, access, and maintain data so that bad data risk is minimized.
- Conduct regular data audits to find inconsistencies and outdated data before complications arise.
- Regulate the data entry processes by setting up standards, data validation rules, and standard formats and templates across the organization to minimize human errors.
- Well-informed employees tend to make minimal mistakes during data handling and management. So, regular training and updating sessions are necessary to keep the employees aware of the standard processes.
- Regularly back up data to prevent data losses during unforeseen events.
- Use advanced tools designed specifically for data validation to assure the consistency and integrity of your data. They can provide confirmation on the accuracy and completeness of your data, detecting and correcting potential errors.
Wrapping Up
This article explored what bad data is, the different types of bad data you may encounter, and their causes. In addition, it highlighted the significant negative impact of bad data on a data-driven organization, from financial losses to business failures. Understanding these factors is the first step in preventing bad data.
Even though there are multiple preventive strategies to ensure data quality, employing a reliable tool specifically designed for the cause is bound to take the load off your shoulders.
Consider using data scraping tools that let you automatically build reliable and clean datasets. This takes the effort out from your end, and leaves you with clean, and directly usable data. One such tool that does this is the Web Scraper API by Bright Data. Not interested in dealing with scraping at all? Register now and download our free dataset samples!





