

In this tutorial on tricks for scraping Next.js sites, you will learn:
- What is Next and why it is so popular
- Why it is easy to scrape Next.js web pages thanks to how React hydration works
- How to harness React hydration for web scraping
Let’s dive in!
What Is Next.js and How Does It Work?
Next.js is a JavaScript framework built on top of React for building server-side rendered and statically generated websites. It simplifies the development process by providing a rich API and a structured approach to building server-side React applications.
Next.js has gained a lot of popularity over the years, becoming the fifth most used web library according to Statista. This is due to its ease of use, great performance, similarities with React, extensive documentation, and community support. No wonder many large companies and startups choose Next.js for their web development needs.
At a high level, Next.js works by retrieving data on the server and passing it to React components to create pre-rendered HTML documents. This process enhances performance by generating HTML content on the server, which can then be sent to the client for faster initial page loads.
How To Take Advantage of React Hydration for Web Scraping
Hydration bridges the gap between server-side and client-side rendering. In detail, Next.js hydration is the process through which the HTML document generated by Next.js is converted into a fully functioning client-side React application.
During hydration—after the browser loads the HTML page returned by the server—React adds interactivity to the page. Specifically, it attaches event listeners and handles state in the DOM nodes that correspond to the React components rendered on the server.
These are the steps required by React to hydrate a pre-rendered page:
- Initial server rendering: The server generates the HTML document with the HTML representation of the React components used on the page.
- Client-side JavaScript execution: When the client receives the HTML markup, it runs the JavaScript bundle containing the React code.
- Reconciliation: React compares the HTML returned by the server with the virtual DOM representation generated on the fly. Learn more on the official docs.
- Hydration: If the two are the same, React completes the rendering by adding event handlers and handling state while reusing as much of the existing DOM as possible.
To perform this operation, React needs the same data used by the server to generate the HTML document. Here is why Next.js adds some special DOM elements containing the props data to the generated page.
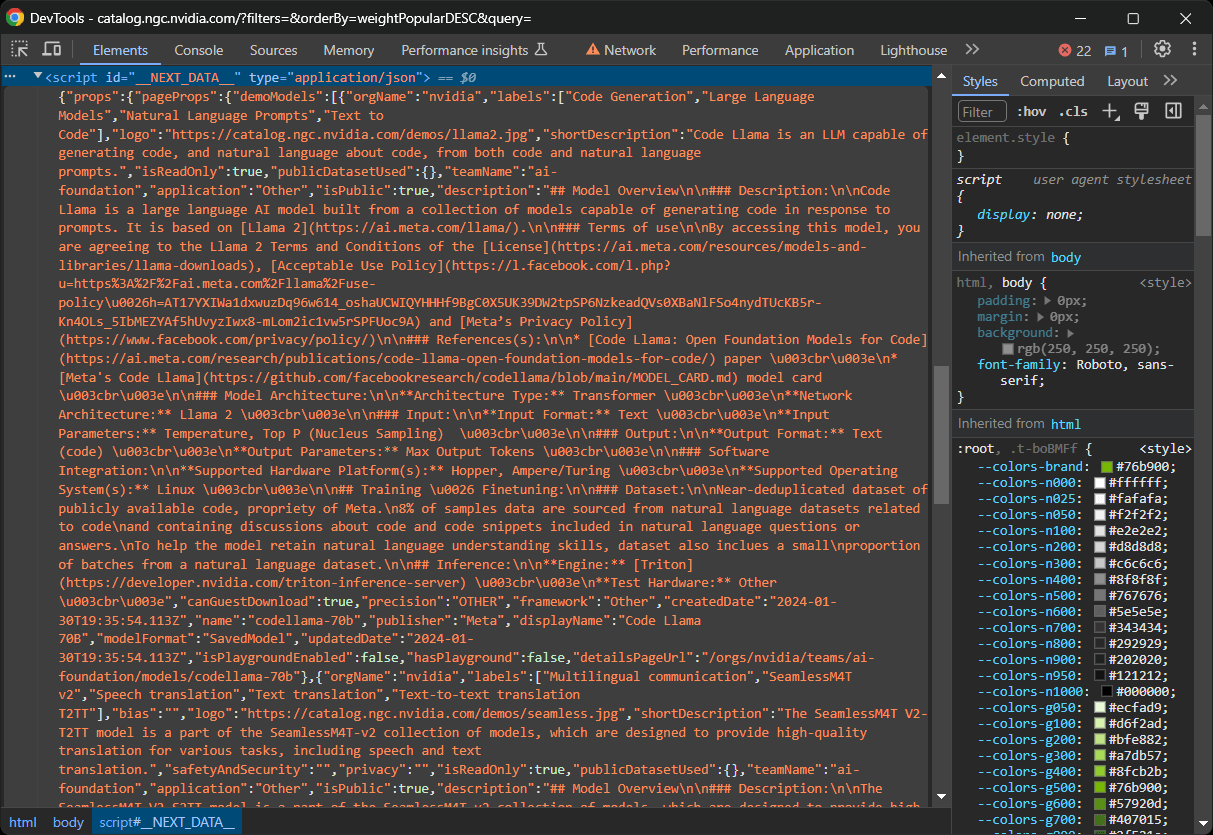
On some Next.js sites, you can find this data in the <script> element with the __NEXT_DATA__ ID. This special DOM node contains data in JSON format that React uses for hydration, as follows:
On recent Next.js sites that utilize the new App Router, hydration data is instead stored in the self.__next_f.push() function calls in multiple <script> nodes:

Note that these nodes may contain even more data than what is displayed on the site. How is this possible? Because those hydration elements store all API and database data retrieved from the server during page generation and passed to React components. However, not all attributes of those objects may actually be accessed and used in the components.
Now, it does not matter if you actually understood why that data needs to be there for React to work. What matters is that the web pages generated via Next.js contain the data to be rendered in JSON format within special DOM nodes. As you can imagine, this has huge implications for Nex.js web scraping!
Scraping Next.js Sites Through the Hydration Data
Extracting data from a page built in Next.js is so easy that you do not even need a scraping script. The DevTools of your browser will be enough.
Let’s now see how to take advantage of React hydration to scrape Next.js sites in seconds!
Extracting Data From __NEXT_DATA__
Suppose you verified that the target page to scrape is built with Next.js (find out how in the FAQ question).
Now, visit the page in your browser, right-click, and select “Inspect” to reach the DevTools. Move to the Console tab and run the JavaScript line below to select the desired <script> element:
const scriptNode = document.querySelector("#__NEXT_DATA__")This will use the querySelector() function to select the element in the DOM with ID __NEXT_DATA__ and assign it to the scriptNode variable.
If you type scriptNode in the console and press Enter, you will get the desired node:

Access its inner HTML content and parse it as JSON content with:
const jsonData = JSON.parse(scriptNode.innerHTML)
Et voilà! The jsonData object will now contain all the data React used to render the components on the page:

In detail, focus on the pageProps field inside props:
jsonData.props.pageProps
Next, right-click on the object and select the “Copy object” option:

Lastly, create a data.json file and paste the desired content to it!
Great! You just performed web scraping on a Next.js site in under a minute.
Put it all together, and you will get this Next.js scraping script:
const scriptNode = document.querySelector("#__NEXT_DATA__")
const jsonData = JSON.parse(scriptNode.innerHTML)
jsonData.props.pagePropsRetrieving Data From self.__next_f.push Functions
Next.js 13 introduced the App Router. This changes the way Next.js delivers the data to React for hydration. In this case, you need to select all <script> nodes that contain the self.__next_f.push string.
Again, visit the target page in the browser and reach the console. Launch the command below to select the <script> nodes:
const scriptNodes = document.querySelectorAll("script")querySelectorAll() returns a NodeList object. Convert it to an array with Array.from() to apply the filter() method and get only the nodes of interest:
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))Now, the hydrationScriptNodes will contain all hydration <script> elements on the page:

However, you generally want only the node that has the initialTree attribute. This is where all hydration data of interest is stored:

Select it with:
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))Then, extract the data of interest with:
scriptNode.innerHTMLNote that the retrieved data contains the info of interest but requires additional parsing. You can convert it to a more readable format with a few extra lines.

This time, the Next.js scraping script is:
const scriptNodes = document.querySelectorAll("script")
const hydrationScriptNodes = Array.from(scriptNodes).filter((e) => e.innerHTML.includes("self.__next_f.push"))
const scriptNode = hydrationScriptNodes.find((e) => e.innerHTML.includes("initialTree"))
scriptNode.innerHTMLCongratulations! Scraping Next.js sites has never been easier!
Limitations of This Next.js Scraping Approach
While this scraping approach based on React hydration data is quick and effective, it comes with some limitations. These are:
- Partial data: The special nodes
<script>nodes added by Next.js only contain the data retrieved by the server and passed to the React components during hydration. That may not be the entire data contained on the page. This is because React components can have hardcoded values or retrieve other data dynamically via AJAX. In this case, you need to perform web scraping with a browser automation tool. - Extra parsing required:
self.__next_f.pushinvolves data in a proprietary format, and parsing it correctly may not always be easy. - Requires manual operations: Unless you translate the scripts written above into scraping scripts in JavaScript, Python, or similar language and integrate the logic for data export, you must export the data manually into a text file. Find out more in our web scraping with JavaScript and Node.js guide.
Conclusion
In this article, you learned what Next.js is, why it is one of the most widely used technologies in the world for building sites, and how to scrape data from it. In particular, you realized that it relies on React hydration and what that entails. Because of that, the HTML pages returned by the server already contain all the data you need (and even in JSON format!). This makes web scraping Next.js sites very easy.
The real problem is another one: getting blocked by anti-bot technologies. These systems can detect and block your automated scraping script. Fortunately, Bright Data has several effective solutions for you:
- Web Scraper IDE: A cloud IDE to build web scrapers that can automatically bypass and avoid any blocks.
- Web Scraper API: Access structured web data programmatically with ease, featuring 99.99% uptime and unlimited scalability.
- Scraping Browser: A cloud-based controllable browser that offers JavaScript rendering capabilities while handling CAPTCHAs, browser fingerprinting, automated retries, and more for you. It integrates with the most popular automation browser libraries, such as Playwright and Puppeteer.
- Web Unlocker: An unlocking API that can seamlessly return the raw HTML of any page, circumventing any anti-scraping measures.
Don’t want to deal with web scraping at all but are still interested in online data? Explore Bright Data’s ready-to-use datasets!
FAQ
Is it possible to hide or remove __NEXT_DATA__ from the DOM in Next.js?
No, you cannot remove or hide that. If you decided to remove the _NEXT_DATA_ <script> element from the DOM, React would not be able to hydrate. As the data in that script is required by React to work properly, you cannot remove it without expecting some malfunction or degradation of functionality. Read the GitHub discussion dedicated to this topic.
Is it possible to remove self.__next_f.push calls from the DOM?
No, you cannot remove the self.__next_f.push calls in the <script> nodes added by Next.js. Those DOM elements are added by the server to make the client-side React application able to hydrate and function as expected. For more details, check out the GitHub discussion dedicated to that topic.
How to tell if a site is built in Next.js?
There are a few ways to tell that a site is built with Next.js. First, look for the X-Powered-By header set by default by some versions of Next.js:

Otherwise, check whether the DOM contains a <script id="__NEXT_DATA__" ... > node or some <script>self.__next_f.push(...)</script> nodes.
Is Next.js the only technology that relies on React hydration?
No, Next.js is not the only technology that relies on React hydration. Other server-side rendering (SSR) generators, such as Gatsby, also utilize React hydration to convert server-rendered HTML into interactive React applications on the client side. This process is a common approach in SSR with React and is not limited to Next.js.

Technical Writer
Antonello Zanini is a technical writer, editor, and software engineer with 5M+ views. Expert in technical content strategy, web development, and project management.



