
- API based scraper
Use our interface to build your api request - Automation in scale
Build your own scheduler to control the frequency - Delivery
Deliver the data to your preferred storage or download it



Web Scraping API
The most reliable Web Scraping API. Scrape any website with automatic proxy rotation, anti-bot bypass, and JavaScript rendering. Start with 1000+ ready-made scrapers for popular platforms.
No credit card required

1247 scrapers
- Scrape real-time data via API
- Pay only for successfully delivered results
- Bulk request handling, up to 5K URLs
- Retrieve results in multiple formats
Trusted by 20,000+ customers worldwide
Effortlessly scrape web data

Web Scrapers API
Web Scraper API Library
Remove the need to develop and maintain the infrastructure. Simply extract high volume web data, and ensure scalability and reliability using our Web Scraper API.
LinkedIn people profiles
ID, Name, City, Country code, Position, About, Posts, Current company, and more.
 117.8K+
117.8K+ 11.1K+
11.1K+Amazon products
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by best sellers category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific keywords
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - find products by using upc numbers
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
LinkedIn company information
ID, Name, Country code, Locations, Followers, Employees in linkedin, About, Specialties, and more.
Instagram - Profiles
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Instagram - Profiles - Collect profile information by user name
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Crunchbase companies information
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Crunchbase companies information - Searching data by keyword
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Linkedin job listings information
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover new jobs by keyword
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover jobs by company URL
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Instagram - Posts
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Instagram - Posts - Collects posts from a specific URLs by using profile URL
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Google Maps full information
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - discover records by location search
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Collect Google Maps Businesses data by place id
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Discover new records by Customer ID
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Zillow properties listing information
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Discover by custom filters - location, home type and status
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Search by parameters on zillow and use the direct link as input
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
LinkedIn posts
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover user's articles by URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover posts by Profile URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover new posts company URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
X (formerly Twitter) - Posts
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Collecting Twitter posts URLs
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Getting x posts by array of profiles
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
TikTok - Profiles
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
TikTok - Profiles - Discover by search URL and country
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
Youtube - Videos posts
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search new youtube videos by keyword
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discover videos by channel URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search videos by keyword and then apply relevant video filters
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Collect YouTube posts by hashtags
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery records by Explore page URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery videos by podcast url
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Amazon Reviews
URL, Product name, Product rating, Product rating object, Product rating max, Rating, Author name, Asin, and more.
TikTok - Posts
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Input specific profile URL to get posts published by it
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Search posts by specific keyword or hashtag
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - discover new records by TikTok discover URL
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Facebook - Pages Posts by Profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Indeed job listings information
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Collect new jobs by keyword search in specific location
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Discover jobs by company URL
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Walmart - products
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Find new products by using specific category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Collects products by specific keywords
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Discover products by using sku numbers
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
TikTok Shop
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - category
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - Collect TikTok shop products by keywords search
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - discover records by shop url
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
YouTube - Channels
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
YouTube - Channels - Collects channel by keyword related to the channel or video's of the channel
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
Reddit- Posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover Reddit posts by Subreddit URL
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discovery by keyword of Reddit posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover posts by author
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Glassdoor companies overview information
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - Search for companies by keyword
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover new companies by input filters
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover by search url
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Google maps reviews
URL, Place id, Place name, Country, Address, Review id, Reviewer name, Reviews by reviewer, and more.
Instagram - Reels
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Discover reels video from Instagram profile or direct search url
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Collect all Reels from Instagram profiles (without the post timestamp)
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Airbnb Properties Information
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Search Airbnb by location
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Discover by search url
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
X (formerly Twitter) - Profiles
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
X (formerly Twitter) - Profiles - Collect profile information by user name
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Glassdoor companies reviews
Overview id, Review id, Review url, Rating date, Count helpful, Count unhelpful, Employee job end year, Employee length, and more.
Booking Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings -
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Yahoo Finance business information
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Yahoo Finance business information - Discover records by keyword
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Instagram - Comments
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
Web Scraper API Pricing
Only pay for what’s successfully delivered. No hidden fees, no charges for failed deliveries.
We accept these payment methods:
Every plan gives you full access - pay less per record as you scale
Data Collection
- Automated proxy management
- Full browser rendering
- CAPTCHA solving
Performance at Scale
- Unlimited concurrency
- Batch & scheduled collection
- Job management APIs
Data Delivery
- Data validation & discovery
- Data parsing (JSON or CSV)
- Webhook or API delivery
Proxy-Based Scraper vs. Web Scraper API
Bright Data
CODE EXAMPLES
Dedicated endpoints for 250+ domains.
Input
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.linkedin.com/in/elad-moshe-05a90413/"},{"url":"https://www.linkedin.com/in/jonathan-myrvik-3baa01109"},{"url":"https://www.linkedin.com/in/aviv-tal-75b81/"},{"url":"https://www.linkedin.com/in/bulentakar/"},{"url":"https://www.linkedin.com/in/nnikolaev/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l1viktl72bvl7bjuj0&format=json&uncompressed_webhook=true"
Output
JSON
[
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "ane***-ka***m-8*********",
"name": "aneesa k****m",
"city": "South Africa",
"country_code": "ZA",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "lil***ia-***b0a******",
"name": "Lili ***",
"city": "Algeria",
"country_code": "DZ",
"position": "Aide chez Citi",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "ber***is-***y-8*********",
"name": "berkhais m**y",
"city": "Nabeul, Tunisia",
"country_code": "TN",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "san***p-k***r-y*********eep******************",
"name": "sandeep k***r y***v s*****p k***r",
"city": "Kakori, Uttar Pradesh, India",
"country_code": "IN",
"position": "--",
"about": null
},
{
"db_source": "1784202467790",
"timestamp": "2026-07-16",
"id": "mar***n-s***iag*********69",
"name": "Maryann S******o",
"city": "Philippines",
"country_code": "PH",
"position": "Supervisor Assistant at SMK Electronics",
"about": null
}
]
Input
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","asin":"B0CRMZHDG8","origin_url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","zipcode":"94107","language":""},{"url":"https://www.amazon.com/KitchenAid-Protective-Dishwasher-Stainless-8-72-Inch/dp/B07PZF3QS3","asin":"B07PZF3QS3","zipcode":"","language":""},{"url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","asin":"","origin_url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","zipcode":"94124","language":""}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l7q7dkf244hwjntr0&format=json&uncompressed_webhook=true"
Output
JSON
[
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Retro Wildwood New Jersey Waves Sun Ocean Beach NJ Vacation T-Shirt",
"seller_name": "Ama***.co***",
"brand": "Wildwood NJ Design Co",
"description": "Retro Wildwood New Jersey Waves Sun Ocean Beach NJ Vacation Design. Buy This For Yourself Or Someone Who Loves To Vacati...",
"initial_price": 19.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "SP Hydrate Shampoo 500ml",
"seller_name": "Glo***Hai***",
"brand": "Wella Professionals",
"description": "Produktbeschreibung SP Hydrate Shampoo 500ml Gebrauchsanweisung Das Shampoo auf nasses Haar auftragen, sanft einmassiere...",
"initial_price": 14.88,
"currency": "EUR"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Jewelry Making for Beginners: A Step-by-Step Guide to Wirework, Stone Setting, Chainmaille, Clasps, Mixed Media, Finishi...",
"seller_name": null,
"brand": "Annika Blake",
"description": "Jewelry Making for BeginnersTurn simple materials into beautiful, wearable creations with confidence.Jewelry Making for ...",
"initial_price": 4.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "Sound Dampening Foam Panels, 6 Pack 48\u0022 x 24\u0022 x 2\u0022 High Density Egg Crate Foam, Acoustic Sound Proofing Wall Panels for ...",
"seller_name": "Xinyang J****i T*****g C**, L**.",
"brand": "Evovoce",
"description": "About this item Noise Reduction Panels:Evovoce egg crate foam panels help reduce echo, reverberation, and reflected soun...",
"initial_price": 79.99,
"currency": "USD"
},
{
"db_source": "1784208906131",
"timestamp": "2026-07-16",
"title": "51mm Coffee Distributor, Tamper Leveler Espresso Tamper,Coffee Distribution Tool Adjustable Height,Espresso Accessories ...",
"seller_name": "FAN***SI",
"brand": "Fixiooz",
"description": "51mm Coffee Distributor",
"initial_price": 16.99,
"currency": "USD"
}
]
Input
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.zillow.com/homedetails/2506-Gordon-Cir-South-Bend-IN-46635/77050198_zpid/?t=for_sale"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lfqkr8wm13ixtbd8f5&format=json&uncompressed_webhook=true"
Output
JSON
[
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 120742808,
"city": "Charleston",
"state": "SC",
"homeStatus": "RECENTLY_SOLD",
"address:city": "Charleston",
"address:streetAddress": "1119 Oak Overhang St"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 447697956,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "4091 Briars Creek Ln"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 10861113,
"city": "Johns Island",
"state": "SC",
"homeStatus": "OTHER",
"address:city": "Johns Island",
"address:streetAddress": "4966 Green Dolphin Way"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 110231160,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "55 Cotton Hall"
},
{
"db_source": "1784192189126",
"timestamp": "2026-07-16",
"zpid": 10857946,
"city": "Johns Island",
"state": "SC",
"homeStatus": "SOLD",
"address:city": "Johns Island",
"address:streetAddress": "1374 Dunlin Ct"
}
]
Input
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.instagram.com/p/Cuf4s0MNqNr"},{"url":"https://www.instagram.com/p/DP861NijuwE"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lk5ns7kz21pck8jpis&format=json&uncompressed_webhook=true"
Output
JSON
[
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DREdllLDePe",
"user_posted": "paulziemiak",
"description": "Viva Polonia an Rhein und Ruhr! \n 🇩🇪 🇵🇱 \n\nWusstet ihr, dass Millionen Menschen in Nordrhein-Westfalen polnische Vorf...",
"hashtags": [
"#NRW."
],
"num_comments": 11,
"date_posted": "2025-11-15T08:03:54.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DJeauFvT6GZ",
"user_posted": "theindianidiot",
"description": "🙏🏾",
"hashtags": null,
"num_comments": 350,
"date_posted": "2025-05-10T13:47:56.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/reel\/DQwBJGXCEbg",
"user_posted": "gretchenrole",
"description": "+32 🎂 \n#harrypotter #harrypottercake",
"hashtags": [
"#harrypotter",
"#harrypottercake"
],
"num_comments": 123,
"date_posted": "2025-11-07T08:49:40.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/reel\/DQpbapXjtak",
"user_posted": "bb.realestates",
"description": "Wie läuft die Vermarktung in Zusammenarbeit mit Berenfänger \u0026 Bechtold ab?👨🏻💻\n\n#bbrealestate #berenfaengerbechtold #...",
"hashtags": [
"#bbrealestate",
"#berenfaengerbechtold",
"#immobilien",
"#architecture",
"#realestate",
"#luxuryhomes",
"#interior",
"#immobilienmakler"
],
"num_comments": 0,
"date_posted": "2025-11-04T20:06:25.000Z"
},
{
"db_source": "1784143874161",
"timestamp": "2026-07-15",
"url": "https:\/\/www.instagram.com\/p\/DQN2K_UgRU0",
"user_posted": "eluniversalmx",
"description": "Con una sonrisa en el rostro y saludando al público, Pato entró con un saco de color negro con distintos diseños que rea...",
"hashtags": null,
"num_comments": 0,
"date_posted": "2025-10-25T03:00:30.000Z"
}
]
BEST-IN-CLASS DX
Easy to start. Easier to scale.
Unmatched Stability
Ensure consistent performance and minimize failures by relying on the world’s leading proxy infrastructure.
Simplified Web Scraping
Put your scraping on auto-pilot using production-ready APIs, saving resources and reducing maintenance.
Unlimited Scalability
Effortlessly scale your scraping projects to meet data demands, maintaining optimal performance.

Leading the way in ethical web data collection
We have set the gold standard for ethical and compliant web data practices. Our peer network is built on trust, with every member personally opting in and the guarantee of zero personal data collection. We champion the collection of only publicly available data, backed by an industry-leading Know Your Customer process and a transparent Acceptable Use Policy. Our global, multilingual Compliance & Ethics team, the first of its kind, ensures we stay ahead of regulatory changes and best practices.
DEPLOY FASTER
Scrape Web with one API call
Data Discovery
Detecting data structures and patterns to ensure efficient, targeted extraction of data.
Bulk Request Handling
Reduce server load and optimize data collection for high-volume scraping tasks.
Data Parsing
Efficiently converts raw HTML into structured data, easing data integration and analysis.
Data validation
Ensure data reliability and save time on manual checks and preprocessing.
UNDER THE HOOD
Never worry about proxies and CAPTCHAs again
- Automatic IP Rotation
- CAPTCHA Solver
- User Agent Rotation
- Custom Headers
- JavaScript Rendering
- Residential Proxies
Every 15 minutes, our customers scrape enough data to train ChatGPT from scratch.
API for Seamless Web Data Access
Comprehensive, Scalable, and Compliant Web Data Extraction
API for Seamless Web Data Access
Comprehensive, Scalable, and Compliant Web Data Extraction
Tailored to your workflow
Get structured data in JSON, NDJSON, or CSV files through Webhook or API delivery.
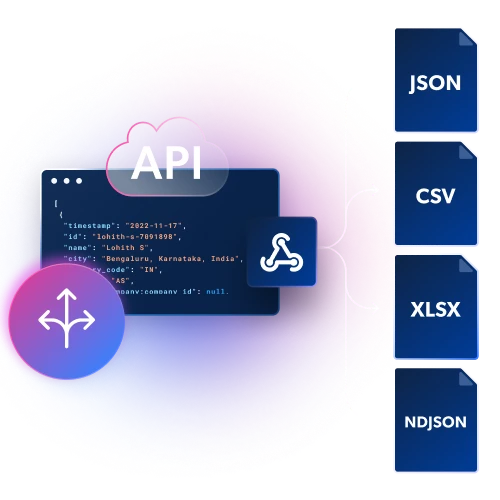
Built-in infrastructure and unblocking
Get maximum control and flexibility without maintaining proxy and unblocking infrastructure. Easily scrape data from any geo-location while avoiding CAPTCHAs and blocks.

Battle-proven infrastructure
Bright Data’s platform powers over 20,000+ companies worldwide, offering peace of mind with 99.99% uptime, access to 400M+ real user IPs covering 195 countries.

Industry leading compliance
Our privacy practices comply with data protection laws, including the EU data protection regulatory framework, GDPR, and CCPA.

USE CASES
Scraper APIs for every use case





Web Scraper API FAQs
What are Web Scraper APIs?
Web Scraper APIs is a cloud-based service that simplifies web data extraction, offering automated handling of IP rotation, CAPTCHA solving, and data parsing into structured formats. It enables efficient, scalable data collection, tailored for businesses needing to access valuable web data seamlessly.
Who can benefit from using Web Scraper APIs?
Data analysts, scientists, engineers, and developers seeking efficient methods to collect and analyze web data for AI, ML, big data applications, and more will find Web Scraper APIs particularly beneficial.
Why choose Web Scraper APIs over manual scraping methods?
Web Scraper APIs overcome the limitations of manual web scraping, such as dealing with website structure changes, encountering blocks and captchas, and the high costs associated with infrastructure maintenance. It offers an automated, scalable, and reliable solution for data extraction, significantly reducing operational costs and time.
What makes Bright Data’s Web Scraper APIs unique in the market?
The uniqueness of Web Scraper APIs lies in its specialized features like Bulk Request Handling, Data Discovery, and Automated Validation, backed by advanced technologies including Residential Proxies and JavaScript Rendering. These capabilities ensure broad access, uphold high data integrity, and enhance overall efficiency, distinguishing Scraper APIs in the competitive landscape.
How can I get started with Web Scraper APIs?
Getting started with Web Scraper APIs is straightforward via Bright Data’s control panel, which provides comprehensive documentation and a user-friendly dashboard for API key management and settings. This approach minimizes setup requirements, allowing immediate access to a platform that is highly scalable and reliable for web data extraction needs.
What specific use cases are Web Scraper APIs optimized for?
Web Scraper APIs support a range of development needs including competitive benchmarking, market trend analysis, dynamic pricing algorithms, sentiment extraction, and feeding data into machine learning pipelines. Essential for e-commerce, fintech, and social media analytics, these APIs empower developers to implement data-driven strategies effectively.
How does Web Scraper APIs manage large-scale data extraction tasks?
Featuring capabilities for high concurrency and batch processing, Web Scraper APIs excel in large-scale data extraction scenarios. This ensures developers can scale their scraping operations efficiently, accommodating massive volumes of requests with high throughput.
In which data formats can Web Scraper APIs provide extracted information?
Web Scraper APIs deliver extracted data in versatile formats including NDJSON and CSV, ensuring seamless integration with a wide array of analytics tools and data processing workflows, thus facilitating easy adoption in developer environments.