







Web Scraper IDE
Reduza o tempo de desenvolvimento e garanta uma escala ilimitada com nosso IDE para Raspador da Web, incorporado em nossa infraestrutura de proxy de desbloqueio.
![]()

- 73+JavaScript functions prontas a usar
- 38K+ Raspadores construídos por os nossos clientes
- 195Países com pontos finais de proxy

Contornar facilmente CAPTCHAs e bloqueios
A nossa solução alojada proporciona-lhe o máximo controlo e flexibilidade sem ter de manter uma infraestrutura de proxy e de desbloqueio. Raspe facilmente dados de qualquer localização geográfica e evite CAPTCHAs e bloqueios.
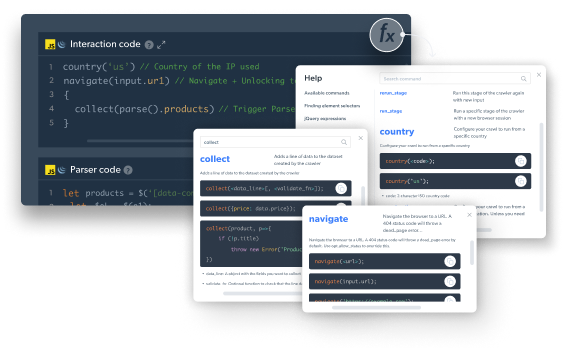
Use code templates and pre-built JavaScript functions
Reduza substancialmente o tempo de desenvolvimento utilizando funções JavaScript prontas e modelos de código de grandes sites para construir seus web scrapers de forma rápida e escalável.
Tudo o que precisa de uma solução de raspagem da web


Características do IDE para Raspador da Web
Modelos de raspadores da web pré-fabricados
Comece rapidamente e adapte o código existente às suas necessidades específicas.
Pré-visualização interativa
Observe o seu código enquanto o cria e depure rapidamente os erros no seu código.
Ferramentas de depuração incorporadas
Depure o que aconteceu num rastejamento anterior para compreender o que precisa de ser corrigido na próxima versão.
Script de navegador em JavaScript
Trate o controlo do navegador e os códigos de análise com JavaScript procedural simples.
Funções prontas a usar
Capture chamadas de rede do navegador, configure um proxy, extraia dados da interface de carregamento preguiçoso e muito mais.
Fácil criação de analisadores
Escreva os seus analisadores em cheerio e faça pré-visualizações ao vivo para ver que dados produziu.
Infraestrutura de escala automática
Não é necessário investir no hardware ou software para gerir um raspador de dados de rede de nível empresarial.
Proxy e Desbloqueio Incorporado
Emule um usuário em qualquer geolocalização com impressões digitais incorporadas, novas tentativas automáticas, resolução de CAPTCHA, e muito mais.
Integração
Desencadeie o rastreio num horário ou por API e ligue a nossa API às principais plataformas de armazenamento.
Começando a partir de $2.4 / 1000 carregamentos de página
- Plano de pagamento conforme o uso disponível
- Sem taxas de configuração ou taxas ocultas
- Descontos por volume
Processo de coleta de dados
Para descobrir uma lista completa de um produto dentro de uma categoria ou em todo o sítio web, terá de executar uma fase de descoberta. Use as nossas funções prontas para a pesquisa do sítio e clique no menu de categorias, como por exemplo:
- Extração de dados de pesquisa de carga preguiçosa (load_more(), capture_graphql())
- Funções de paginação para a descoberta de produtos
- Apoio ao empurrar novas páginas para a fila de raspagem paralela utilizando rerun_stage() ou next_stage()
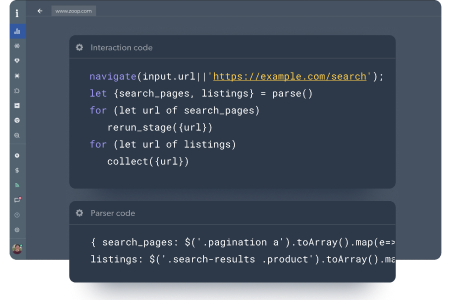
Construa um raspador para qualquer página, usando URLs fixos, ou URLs dinâmicos usando uma API ou diretamente da fase de descoberta. Alavanque as seguintes funções para construir um raspador de rede mais rapidamente:
- Análise de HTML (em cheerio)
- Capturar chamadas de rede do navegador
- Ferramentas pré-construídas para APIs de GraphQL
- Raspar as APIs JSON de sítios web
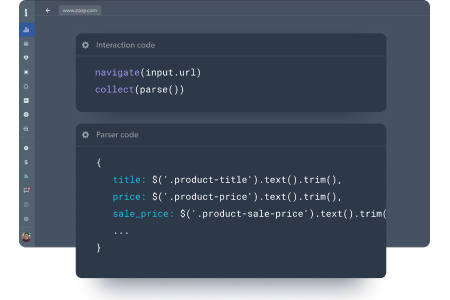
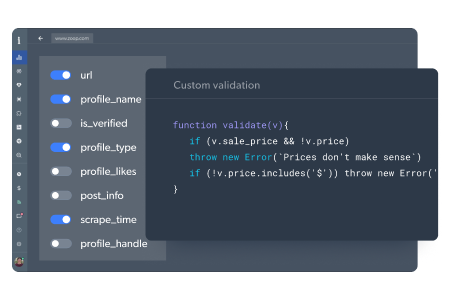
Um passo crucial para garantir a receção de dados estruturados e completos
- Defina o esquema de como deseja receber os dados
- Código de validação personalizado para mostrar que os dados estão no formato correto
- Os dados podem incluir JSON, ficheiros multimédia e capturas de ecrã do navegador
Entregue os dados através de todos os destinos de armazenamento populares:
- API
- Amazon S3
- Webhook
- Microsoft Azure
- Google Cloud PubSub
- SFTP
Concebido para qualquer caso de utilização
Raspador de sítios web de comércio eletrónico
- Configurar modelos dinâmicos de preços
- Identificar os produtos correspondentes em tempo real
- Acompanhar as mudanças na procura dos consumidores
- Antecipar as próximas grandes tendências de produtos
- Receber alertas em tempo real quando novas marcas são introduzidas
Raspador de sites de redes sociais
- Raspar gostos, publicações, comentários, hashtags e vídeos
- Descobrir influenciadores por # de seguidores, indústria e mais
- Mudanças pontuais na popularidade através da monitorização de gostos, partilhas, etc.
- Melhorar as campanhas existentes e criar campanhas mais eficazes
- Analisar análises de produtos e feedback dos consumidores
Raspador de sítios web de negócios
- Raspador de sítios de geração de pistas e empregos
- Raspar perfis públicos para atualizar o seu CRM
- Identificar as principais empresas e movimentos de trabalhadores
- Avaliar o crescimento da empresa e as tendências da indústria
- Analisar padrões de contratação e conjuntos de competências a pedido
Raspador de sítios web de viagens, hospitalidade e turismo
- Comparar preços de hotéis e viagens da concorrência
- Definir modelos dinâmicos de preços em tempo real
- Encontrar novas ofertas e promoções dos seus concorrentes
- Determinar o preço certo para cada promoção de viagem
- Antecipar as próximas grandes tendências de viagem
Raspador de sítios web imobiliários
- Comparar preços de propriedades
- Manter uma base de dados atualizada de listagens de propriedades
- Previsão das vendas e tendências para melhorar o ROI
- Analisar ciclos de aluguer negativos e positivos do mercado
- Localizar imóveis com as taxas de aluguer mais elevadas
Diretório do Raspador da Web

Conformidade líder na indústria
Наши методы конфиденциальности соответствуют законам о защите данных, включая регуляторный фреймворк по защите данных ЕС, GDPR и CCPA – с уважением к запросам на осуществление прав на конфиденциальность и другое.
FAQ
O que é o IDE para Raspador da Web?
O IDE para Raspador da Web é uma solução totalmente hospedada na nuvem, concebida para os programadores construírem raspadores rápidos e escaláveis num ambiente de codificação JavaScript. Criado com base na solução de proxy de desbloqueio da Bright Data, o IDE inclui funções prontas e modelos de código dos principais sítios web, reduzindo o tempo de desenvolvimento e garantindo um escalonamento fácil.
A quem se destina o IDE para Raspador da Web?
Ideal para clientes que dispõem de capacidades de desenvolvimento (internas ou externas). Os usuários do IDE para Raspador da Web têm o máximo controlo e flexibilidade, sem necessidade de manter uma infraestrutura, lidar com proxies e sistemas antibloqueio. Os nossos usuários podem facilmente escalar e desenvolver raspadores rapidamente utilizando funções de JavaScript pré-construídas e modelos de código.
O que é que o teste gratuito inclui?
> testes ilimitados
> acesso a modelos de código existentes
> acesso a funções de JavaScript predefinidas
> publicar 3 raspadores, com até 100 registros cada um
**O teste gratuito é limitado pelo número de registros raspados.
Em que formato são entregues os dados?
Escolha entre JSON, NDJSON, CSV ou Microsoft Excel.
Onde são armazenados os dados?
Pode selecionar o seu método de entrega e armazenamento preferido: API, Webhook, Amazon S3, Google Cloud, Google Cloud Pubsub, Microsoft Azure ou SFTP.
Por que os Proxies Residenciais custam mais?
A obtenção de um conjunto de qualidade de Proxies Residenciais leva um tempo e esforço consideráveis. A Bright Data obtém IPs residenciais por meio de desenvolvedores de aplicativos e software que usam nosso SDK para fazer com que seus usuários entrem na rede de proxy. Esses usuários são recompensados em troca de se juntarem à rede.
Por que é que é importante ter uma rede de proxy quando se faz raspagem?
Uma rede de proxy é importante para a raspagem da web porque permite que o raspador permaneça anónimo, evite o bloqueio de IP, aceda a conteúdos com restrições geográficas e melhore a velocidade de raspagem.
Por que razão é importante dispor de uma solução de desbloqueio durante a raspagem?
Ter uma solução de desbloqueio quando se faz raspagem é importante porque muitos sítios web têm medidas antirraspagem que bloqueiam o endereço IP do raspador ou exigem a resolução de CAPTCHA. A solução de desbloqueio implementada no IDE da Bright Data foi projetada para contornar esses obstáculos e continuar coletando dados sem interrupção.
Que tipo de dados posso raspar?
Dados disponíveis ao público. Devido ao nosso compromisso com as leis de privacidade, não permitimos a raspagem por trás dos inícios de sessão.